Hugh Taylor Selections -
One Year On
|
|
Hugh Taylor Selections - One Year On |
|
|
Article 14_001_3
27th January, 2014.
|
This is the second article covering a Study undertaken to assess the angles and methods used by a well known tipster, Hugh Taylor (HT), of the Attheraces website, was chosen as the subject Tipster. Partly because he makes regular selections but, more importantly, he also produces detailed supporting text for each Tip. This means it is at least feasible, unlike with most tipsters, to identify and assign weights to the angles and edges he invokes in support of each selection. HT has also made a profit, at his advised prices, over a period of 5 years which should mean there is a good chance of assessing some real skill being displayed.
The initial 'Interim Article' was written in March 2013 following a period of 2 months of collecting HT's Tips and doing some tentative categorisation of his selections. The Introduction to the First Article gave a detailed description of the development of the ideas which lead to this study. That detail is not going to be repeated here and reading that background text is advisable. For those who lacking the time for that sort of indirection a brief recap follows.
Studies have shown that humans are poor at using available data to predict outcomes in a wide variety of areas. Despite this we continue to believe in our abilities and the procedures we use. This quote is from Daniel Kahneman and taken from the First Article :-
"..We knew as a general fact that our predictions were little better than random guesses,
but we continued to feel and act as if each of our specific predictions was valid.....I coined the term for our experience the illusion of validity."
The 'Illusion of Validity' is enabled by a range of psychological biases that humans have built into them and are used as the 'lazy default action' in most situations. Which means it is hard to recognise faults with your thinking, admit to them, and then change what you actually do. 'Experts' will just plough on doing what they have 'always done' and if any failures in their predictions are pointed out to them they will build a 'Story' to remove the failure rather than attend to their flawed methods and thinking.
A couple of questions that come out of that are, firstly, how does any of the summary in the previous paragraph apply to racing prediction Experts? In this article we will stick to 'Tipsters' as an example but the same questions apply to Pedigree Analysts & Bloodstock Agents, amongst others. A key question is how predictable horse races are and therefore how much skill it is possible to apply to predicting their outcomes. The second question is that if humans are so compromised by their biology are there any ways we can implement procedures to help them overcome the issues? The result of that should be better predictions.
One area that has been studied to improve predictions has been the use of simple checklists and a small number of factors assigned simple scores and then combined. The classic example being to compare just such a simple scored factors algorithm with the diagnoses and recommended treatments from Doctors when patients present at Hospital. It goes against human thinking to believe that a few numbers, which could be taken by a Nurse, and added together can produce better results than a Consultant Doctor with years of experience taking time to review every scrap of data they can find. But, consider this quote, again from Kahneman's book and also in the First Article :-"About 60% of the studies have shown significantly better accuracy for the algorithms.
The other comparisons scored a draw in accuracy, but a tie is tantamount to a win for statistical rules, which are normally
much less expensive to use than expert judgement. No exception has been convincingly documented."
Which hopefully will be enough background to understand why this study was undertaken. The aim being to categorise HT's selections by a small number of factors. Then compare those factors to the actual results in the races where they are invoked as important by HT. A possible outcome being that a small sub-set of factors HT uses show up as worthwhile in aiding prediction. These would then be combined into a simple algorithm to be applied to HT's daily selections to identify which had a higher probablity of success and which were not much above guessing.
During the 2013 Turf Season B2yoR tried running some simple algorithms to make bets alongside the, probably more 'Black Art' and certainly less consistent, methods that had been in use for long periods. It was a painful experience in some ways and very hard work. 'Hard' in one sense because of the extra work involved to run the Algorithms alongside 'business as usual'. But, even harder in having to fight the natural impulse to drop back into the 'Lazy Default' of the usual Race Profiling plus Paddock Review.
The use of Algorithms also proved to be very hard in the sense of the feeling of 'losing control' of your choices. If the algorithm says back one horse and your instinct says do something different the tension between the two can be felt physically. Further, when the 'Black Art' picks fail to win, or even run competitively, the personal knowledge of the data and reasoning used makes it easy to concoct a Story after to race to excuse the loss and paper over the issues. If the Algorithm picks losers you just have to go with it and 'believe' things will come right. That you are playing a long game which will come right later if it was set-up correctly. But, the loss of a sense of 'control' at an immediate level can be tremendously uncomfortable.
Back to Top of Page
The core of the article is section 4. which looks at the results of categorising Hugh Taylor's (HT) selections and then seeing how the breakdowns fare in terms of Strike Rate and Return on Investment when analysed. Before that, sections 2. and 3. do some scene setting with regards to the background to the Study. In this part a chance to record some irritations, the 'Gripes', with HT's selection and publishing procedure which Attheraces (ATR) need to fix. Some are minor, you cannot read every word someone has written, more than once, over the period of a calendar year without finding things that rankle. But, they lead up to a major Gripe, with regards to baseless Pedigree waffling, which will be revisited in the next sub-section and later in the document.
The 'Biases' sub-section is a chance for the Author to put some individual opinions on the table ahead of the analysis. The Study is based around reading HT's selection texts each day and then assigning Factor codes to the text where qualifying points HT uses occur. Often this is a simple process and HT is mostly consistent in how he phrases discussion of particular areas. At times, it can be more of a judgement call as to whether to assign a Factor or not, or to decide which Factor should be the 'Top Level Angle' with another dropped to a second level factor.
This judgement means that it is possible for biases to affect the decisions made no matter how fair the person is trying to be. All initial assignment work is done before the races are run which should limit overt 'fixing' of the assignments. But, it is often possible to read a selection text and know whether it sounds like a weak argument that even HT does not support strongly, or conversely a compelling case where HT is confident. Which means that putting the weak selections into a category which this document author does not believe in, or the reverse, can happen unconsciously.
Section 8. covers how the reader can get access to the data, in various formats, that the Study was based on. It also suggests how some short pieces of external work could help to check the assignments and analysis done in this Study.
The first Gripe is a little arcane but is at the root of the Endnote that Section 7. covers. B2yoR has never fully understood, i.e. intuitively, HT's answer to the question of whether he has a list of 'Possibles' horses each day which then get passed through the Price Level filter to become Selections. When asked, on the 'Form Factor' program in response to an e-mail, HT said that the 'Possibles' list does not exist because the Price Level test is either the first, or very early, consideration in a horse becoming a selection on the day. Which almost suggests that Price Level is always the 'Top Level Edge' in terms of this Study.
This does not make intuitive sense to this author and seems to be putting too much emphasis on the Betting Market. It also seems to imply that the selection text HT writes is back-fitted to a horse which has passed a precursor 'Price Test'. It feels more sensible that horses should have become candidates to be 'of interest', to use HT's terminology, on these basis of the selection methods used. The candidate horses would then have their Market Prices checked as a Yes/No gate after the analysis was complete.
Perhaps this has been misunderstood but if 'Price' is the primary decision point then should not HT be putting up selections in a different form. For example, putting up details of his 'Tissue' for each race and advising multiple bets if horses exceed his Tissue Price in the actual Betting Market.
Next we turn to the 1-5 Points Staking Range which HT does not use. Despite that, ATR persist in using it on the website and in 'Form Factor' conversations. This problem really needs to be solved since the mismatch between HT and the 'ATR Website' is laughable. HT has said that he doesn't ever feel that a selection is worth 5 times more than the basic 1 point staking unit. The '1-5 Points' wording seems to continue because the ATR website want a consistent base across all the Tipsters they employ. If some Tipsters are not using it then it is already inconsistent so time to work at adapting it.
If HT is worried about his own returns that the website reports then what about letting him use a 1-2 point Staking System but make him add a 'Percentage Confidence' tag which had a wider range. This would then allow people who read his articles to adjust their staking levels accordingly. We have to assume they are all adults who know what gambling entails and they should have a wider range to choose from than 1 point or 2. For a Tipster who has encouraged people to use 'Bayesian' thinking and probabilities this should come naturally.
We can link to the next Gripe by considering the wide range of confidence in a selection that HT currently crams into an advised 1 point stake. Read some of his selection texts and you know his heart is not in it. The next one might have the assuredness of a man who knows he has hit upon a real positive lead. Just in case the reader of his text cannot spot the tips he has put up 'because he has to as an employee' he will occasionally start his pieces with some version of "This looks a really unappealing punting day/card....etc". HT then carries on advising a 1 Point stake despite the obvious lack of confidence.
As a test for this Study B2yoR noted the days when the text started with the 'unappealing' caveat. The result was 21 selections with one a non-runner. Two winners at HT advised prices of 16/1 and 4/1 meant a 2 point profit at the recommended 1 points stake. There was a 7 point loss at Starting Price (SP). But the real point is - do not add stuff about something being 'unappealing', either it is worthy of a 1 point selection or it is not. Or, implement 0.5 point stakes or whatever. Which comes back to the point that the HT/ATR '1-5 Point Staking' system is badly broken.
The next Gripe is more directed at the ATR website people than at HT, the selective trumpeting of winning selections while ignoring the large pile of losers. The losers including some real duff bits of thinking, misplaced hopefulness, and so on. HT is always more circumspect when gushing praise is offered to him and will always say that it is the long term results that matter. The ATR website people ought to respect HT's view and not descend into the approach of a 'Captain Fiddle' type Tipster who sells tips for as long as he can until he has to do-a-runner.
Related to the previous point is the use by the ATR people, and HT at times, of the flawed concept of "being in good form..". HT, along with James Willoughby, did an entire afternoon's programme on ATR in late 2012 which covered lots of areas of fallacies around betting. This included a visual demonstration of how 'form' does not exist and assessing HT's tips over a short window of time is pointless. It seems like the people at ATR do not listen to what HT says to a large extent. Which would fit in with the viewpoint that much of the output by the dedicated racing channels is predicated on the basis of 'filling time' without much quality control.
A couple of other Gripes to finish with the first relatively minor. The HT Text submitted each day needs to be checked better for errors and presumably this should be some sort of sub-editing job that ATR undertakes. HT has said that he often writes text the night before and perhaps for horses who do not make the final selection because of price on the morning of the race. In one instance HT wrote up four horses the night before but, probably because he was travelling to London for the 'Form Factor' programme, he sent all four across by mistake which led to four tips.
At one level this is nitpicking although it does give a better impression if there are not errors in the text (hypocritically stated to some extent). HT's text is checked for spelling but this fails to find the words used in the wrong place. For example, the text often contains 'bets' instead of 'best', 'hid' for 'his', 'her' for 'here and so on. This can be misleading with, for example, one error being 'ride' instead of 'rise' which meant the sentence could be read two ways. They can also be funny such as the use of use of 'feint hearted'. Where HT has presumably changed his mind halfway through a sentence there are also cases of missing words or words left in place when they should have been deleted.
The final Gripe is a personal one and it would be interesting to know if it was approved of by others. When HT is asked to recommend books on 'randomness' and other areas of chance events which can be used as input to a person's betting he always starts with 'Fooled By Randomness' by Nassim Nicholas Taleb (NNT) and often includes 'The Black Swan' by the same author. Having recently got around to reading these the B2yoR view would be - Hugh, please recommend something else.
B2yoR finds NNT, no polite way to put this, an insufferable prick. An intellectual snob who has turned 3-4 good points which could be explained in a 10 page pamphlet, into long books which are really an advert for how superior the author is to the rest of us. Filling the books with stories from the Classical Education he has given himself and bouncing around stories, areas and subjects in a 'random' way. The B2yoR view would be only embark on NNT's books after you have read a range of better ones, and even then only after you have had the appropriate training and while wearing the correct 'safety equipment'. Even then, only bother with page 230 onwards in 'The Black Swan' and forget the other one.
Nate Silver's book 'Signal And The Noise' is much better about uncertainty and betting, and also on the shortcomings of the people in the Financial World. There are a raft of better places to start reading about Traders and Trading than Taleb. Rather than reading NNT's take on human psychology read Daniel Kahneman's 'Thinking Fast And Slow' which NNT draws heavily on. 'Future Babble' by Dan Gardner covers the issues with failures of prediction by experts, and Philip Tetlock's work in particular, than NNT does.
Taleb makes great play of his few heroes, like Henri Poincare & Benoit Mandelbrot, but then does not deliver on explaining why they were exceptional. Again, there are better sources available. The book 'Does God Play Dice' is far superior in explaining the range of Poincare's mathematical work and how he had stumbled upon, and recognised the implications of, the maths that became 'Chaos Theory' decades before it was 'discovered' generally.
This is the place in the article to declare a few possible biases which might be introduced because of existing knowledge and opinions. In an ideal case the Study would be run by Hugh Taylor (HT) filling in a form for each selection he makes. He would identify what angles and edges he felt he was using and also give each some form of weighting score. In that case the input data would be biased by HT. But, as a Study of how his methods translated into winner finding success this would not be an issue.
However, HT provides selection text to explain his reasoning which means that these have to be read by another person who then fills in the form based on their decision about which angles & edges are used. Again in an ideal world this would be done by some 'robot program' on a computer if HT's text were always a selection of known phrases bolted together each day. The issue is that of how consistent the person is and whether they introduce errors because of their knowledge and viewpoint.
At the top level you could say that anyone knowing about racing in general had the potential to add a bias on every selection text they read. If they have opinions on the horse, trainer or jockey for example. Probably more important is that they may have views on the angles/edges effectiveness and may 'fix' the assignments. One method of trying to limit this effect has been to ensure all HT text assessment is done prior to the race being run so that the result is unknown. B2yoR can also vouch for the fact that the person who undertook the angle assignments knows very little about racing outside of the 2yo races during the Turf Seaseon. They would have difficulty getting beyond knowing who had won the Classics at the busiest time of the year.
But, when HT ventures into selecting 2yos it can be difficult to set personal knowledge to one side. This means that getting the set of 2yos tips, 46 horses out of around 600 selections, checked by others would be advantageous. When HT has tipped 2yos then the knowledge held can also help to understand how much, or how little, HT actually knows and how much checking has been done. Many people would have the same feeling when a general News programme on TV covers an item of which they have extensive knowledge. The reaction commonly felt is that the report was either plain wrong or such a great simplification that it gave many wrong impressions about the issue.
As an example HT noted in his selection text for the 2yo Rosita on her second outing in 2013 that "... Its interesting to see her trainer fit blinkers on her second start, perhaps suggesting better might have been expected at Nottingham...". Below is a picture of Rosita on her way to the start on that Nottingham debut, miles behind all the other horses and delaying the start of the race :-
 |
Rosita having been immature in the preliminaries and then unhelpful once led onto the course. To the point of the jockey having to get off and jog to the starting stalls. Rather than suggesting 'hidden ability' how about proposing the headgear for her second run were put on to try to get her to behave reasonably? An example of how knowing a lot about the subject means that you start interpreting HT's selection text, and the value of the supporting arguments he has employed, even before the race is run. Also an indication of how much cross-checking HT is undertaking in some areas, before writing his text. How can the Headgear be classified as a positive factor given the knowledge the person holds? A point considered further in the 'Discussion' section.
To complete the Rosita story - she had to be walked to the start again on her second run at Chepstow. She also needed a Stalls Blanket and to be hooded to go into the stalls. After all that work was required to get her into a position to race she then went part berserk in her first-time headgear and tore off in the lead setting much too strong a pace. If we ever get a 'Sectional Time-o-meter' in this country the needle would have been well over into the 'red section' before halfway and the computer's prediction based on the pace that she would fade by 1 furlong from the finish. But, we cannot even get Sectional Times in Britain, let alone display and interpret them in real-time for the audience.
The other two biases are declarations of personal opinions at the outset so that the results and analysis can be read with that information in mind. Regular readers of the website will be aware that B2yoR thinks that the use of the 'Betting Market' as a means of making selections, or invoking movements in it to support or deny a horse's chances, is hugely flawed. It should be avoided unless a person has detailed evidence that moves of a particular type carry any worthwhile information. The 'Market Movers' and similar features on the Racing coverage are really just advertisements for bookmakers. Further, that the items done by the Channel 4 'betting gurus' Stevenson and Lee are more Bookies' Friends features. Perpetuating the myth that there is a 'Betting Jungle' and that bookmakers' livelihoods depend on individual bets or race outcomes. They are big businesses and accountancy firms in reality, but that doesn't make good 'Telly'.
HT invoked the 'Market' as a factor in his selection on 22 occasions that were noted during the Study. As with the other bias areas noted it would clearly be useful to have the category assignments checked by a wider range of people to ensure fairness.
The final bias to declare in advance is related to how pedigrees are 'read' and used in British Racing. B2yoR's general take is that most of that which is used fits under the 'Pedigree Waffle Swindle' banner. As with other areas within racing there is an accepted way that they can be used and talked about that gets you classified as an 'expert'. The big problem is that the larger majority of such usage is based on shaky or unproven foundations. At a fundamental level it makes no reference to the underlying mechanisms by which horses, and all other life on Earth, inherits the features and capacities they display. Also, without acknowledging how much of the racing ability on display in an individual horse is inherited and how much 'made' by the environment it has passed through and the training it has received. The 'Nature versus Nurture' issue.
Follow Pedigree discussions in British Racing and you could think that the role of Deoxyribonucleic Acid (DNA) in Equine inheritance had never been identified. That the field of Genetics did not exist. Never mind the exciting developments in recent years enabled by reading whole Genomes quickly along with the field of Epigenetics. If you went to a Medical Doctor who said he was an expert in 'Human Bodies' but waffled away about diagnosis and treatment of your ailment without acknowledging the existence of cells, vital organs, the blood circulatory system, Hormones, bacteria, viruses, etc., you would know you were talking to a Quack. But, you can have the same lack of knowledge and understanding of the underlying systems in 'Pedigree Analysis' yet be hailed as a Guru. Something is not quite right.
HT, unfortunately, has a strong liking for propagating the 'Sires for Going' Racket with around 70 of his selections in this Study invoking it at some level. There are three levels of importance within the Study framework that these uses could be categorised. This clearly leaves a bit of room for fudging the figures at the unconscious level and therefore the results could do with some external checking.
The 'Sires for Going' Racket, as a specific example of a much wider problem, is so important that a separate sub-section has been put into the Discussion section of this article to deal with it. In short, it does not exist in any worthwhile form despite the nearly universal acceptance of it as a proven fact within British Racing. Any 'evidence' seen, say of the type HT often brings into his selection text, in the form of Strike Rates for Sires and similar, is either dealing with Random Effects or some form of 'self fulfilling action'.
The later sub-section will bring in some worthwhile evidence of the effect not existing. The 'self fulfilling' aspect comes about because the 'Sires for Going' effect is so entrenched in British Racing. In a set-up where even a trainer as intelligent and thoughtful as John Gosden uses stock phrases like "...Natural Swimmer's maternal grandsire is Mud Swimmer therefore she will need soft ground to be seen at her best...." - about a horse that has never run, then clearly there is a lot of scope for unknowing, and unthinking, 'fixing' of the results by racing insiders.
Back to Top of Page
Section 4. that follows goes into the analysis of the category codes in detail and this Section is a place to record some more general points about Hugh Taylor's (HT) selections over the period of the study. To present a scope of the study, to set some general standards to judge the categories against, along with some general interest points. B2yoR understands that the ATR website team have done their own analysis of HT's tipping but has not published any of this material. But, on the assumption it will become public eventually this Section is not going to cover items such as success rates in different race types, for example. The primary target of the Study was to assess success with betting Angles & Edges that were assigned.
HT's selection were collected for the period January 17th, 2013 until January 18th, 2014 with only one day's tips missed (in the busy part of summer Turf season). This period produced a total of 592 horses selected and a total of 594 bets were recommended. The 594 bets were split as follows :-
Out of the total of 594 bets there were 18 Non Runners (NRs) of which 15 were 1 point Win Single bets to bring the final total of those bets to 499. The other 3 NRs were 2 point Win Single bets to make that total 23.
The Table below shows the overall results for the selections in the Study which related to individual horses. There are separate lines for 1 and 2 point Win Singles and another for the Each-way bets HT advised on individual horses.
| Bet Type | Count | Wins | Losers | SR % | % Plcd | Rec Price P/L |
Rec Price ROI |
SP P/L | SP ROI |
| Win Single 1pt | 499 | 85 | 414 | 17.0% | 41.1% | 150.15 | 0.30 | -52.39 | -0.10 |
| Win Single 2pts | 23 | 6 | 17 | 26.1% | 47.8% | 45.00 | 1.96 | 3.16 | 0.14 |
| Each-way Single 1pt | 48 | 2 | 39 | 4.2% | 18.8% | -5.40 | -0.11 | -32.39 | -0.67 |
| Totals :- | 570 | 93 | 470 | 16.3% | 39.5% | 189.75 | 0.33 | -81.62 | -0.14 |
Table 1. - Profit and Loss (P/L), Strike Rate (SR) and Return On Investment (ROI) summaries
The 'Count' column shows the number of individual bets of that type and the next two columns how many of them were winners and how many losers. The disparity of 7 in the 'Each-way Single 1pt' & 'Totals :-' of winners to losers combined versus the 'Count' figure reflects the Each-way bets which did not win but placed so did return the place part of the bet. The 'SR %' column shows the win Strike Rate as a percentage. The next column shows the percentage of selections that made the first three places in their races, including the winners.
The last 4 columns are two pairs showing the same information for the bets. The first pair are for the recommended Price that HT stated as part of his selection text and the second pair for the same bet but at the Starting Price (SP) that the horse was returned at. The 'Profit/Loss' (P/L) shows the actual amount of points made or lost in making those bets. The 'Return On Investment' (ROI) averages that total return across the number of units staked to place all bets.
The ROI is effectively a percentage of each point unit placed, say £1.00, that was won or lost. For example, 0.30 would mean you made a Profit of 30 pence on every £1.00 staked overall. Conversely, -0.10 would mean 10 pence lost on every £1.00 staked. The 'P/L' and 'ROI' figures in the table are coloured as either Green for Profits and Positive ROI returns or Red for Losses and Negative ROIs.
An important message to take from the table is to remember the shape of the figures for the 'Win Single 1pt' bets in the first line. HT returns ROI figures for this large set of bets very close to the overall average. This can then be used as a template to judge the results returned for the Angle/Edge codes in Section 4. A Strike rate around 17.0% with about 40% of selections making the first three places. A profit around 30% at HT's recommended Price and a 10% loss if the best you ever do is get the Starting Price to your stake. That is a reasonable benchmark to take forward.
The figures in the Table are also of general interest. Even though HT returns a very good profit on advised Prices you would still have to sit through 414 losers, for example, to make your profit. Around 60% of his selections will not make the first three. That deserves a bit of thinking about, profitable and well thought of guy, but an awful lot of selections not winning and probably a majority not competing for the win at the end of the race. Really thinking hard about that, and listening to your intuition, can get you to the thinking covered in the Section 7. endnote.
Without getting to that level of thinking it still seems encouraging for a project aimed at improving the returns betting on HT's selection by cutting out the weak selections. If we assume those 414 losers, for 1 point win single bets, cover some sort of range of 'Confidence' from solid cases made down to threadbare I-had-to-tip-something types, then it should be possible to cut out some of the 'garbage'. If you could remove the 'worst case' 100 losers from the 414 you could make a Profit idling around taking SP. If there really is some findable and quantifiable way of ranking HT's selection texts which matches pretty well with how well the horses compete then it should be worth carrying on digging.
A few other general interest points. The following bullet points outline some details around the Price levels of the selections :-
With just two winners in the Each-Way Single bets only Top Notch Tonto's 33/1 (advised price and 22/1 SP) success stopped that area being a disaster. Where would the record have been if Ian McInnes had not been banned and that horse not been switched to trainer Brian Ellison? Which is the wrong way to think about it, probably. All it needed was another couple of long-shots blundering into a lucky win to make that area profitable.
However, it makes the point of how volatile that area is, even following the selections over a period of 366 days does not smooth out the variability. Would you really want to stick with these long priced tips over such a long period of time hoping things would turn out allright? Given they were unprofitable at any level in this Study and badly so at SP would make anyone think about removing them from any System to follow HT's selections. They might prove profitable over a very long period but are too susceptible to long losing runs. Also, too sensitive to missing out on good prices for the very few winning long priced bets that 'make' the whole area even possibly profitable.
[As an aside, at this point you could almost wish you had read the awful Taleb's 'The Black Swan' properly. Does that last paragraph cut across anything in there? This is Mediocristan rather than Extremistan, surely? The profits and losses are bounded, not scalable, so nobody gets wiped out on either side? Still, avoiding reading that book, 4 weeks and counting to finish it, has overcome a great deal of procrastination in finishing a lot of other mundane tasks. Useful book. ]
The Figure below shows the Top Level Angles assigned to each of the horses selected by HT as a Pie Chart. The chart can be read clockwise from top dead centre with the Angles presented in decreasing percentage of use out of the total set of Study selections. The Codes used are described fully in the Appendix to this document.
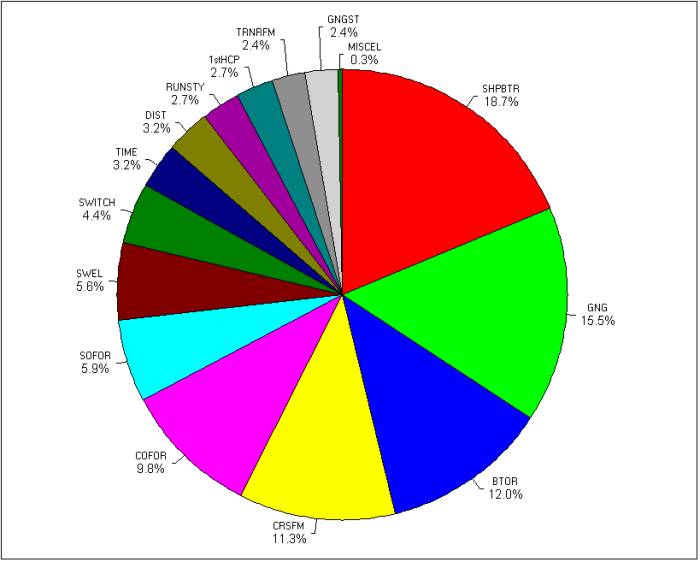 |
Figure 1. - HT Selections split by Top Level Angle Assignment
The first point that stands out is the wide range of Top Level Angles used. The plan at the start of the Study had been to limit the number of Angles used but this did not prove possible. HT really does use a wide range of Angles and in many of the selections texts for the rarely used Angles there was 'nothing' else in the text that could realistically be termed a defining positive Angle. One issue with the high number of Angles is that the sample size to assess in the full analysis is small and therefore would give less robust results.
Despite the long tail of Angles you could say that the Top 4 by usage give a good indication of the 'core' of HT's methods. These account for around 58% of the total. The most used was 'SHPBTR' which is used when HT asserts that a horse has run better in a previous outing, or several runs, than is shown by the final result in the Form Book. These types of selection rely on the huge amount of Race Video Review that HT does. The second most used Angle is 'GNG' for the surface the race is run on. The less often used Angle 'SWEL' for Southwell's unique fibresand surface could also be included in this code but the course is such a favourite of HT they are coded separately.
The third and fourth most used Angles are 'BTOR' for a horse considered to be better than the official rating they run off, and 'CRSFM' for horses selected when returning to a course they have been unusually successful at in previous career runs.
Back to Top of Page
There were two main targets at the commencement of the Study, firstly to develop a systematic way to categorise Hugh Taylor's (HT) selections. Then from that base analyse the results from the different categories to identify ways to improve overall profitability by betting on HT's tips. The results reported in this section are therefore the core of the Study and provide the base for assessing how successful the approach was, what items would be done differently or require extra work, and to identify what simple methods could be applied to HT's future selections to improve profitability.
The decision was taken that the input data to this section should only be the 522 Win Single bets that HT advised over the period. It was noted in Section 3. that the 48 each-way Single Bets produced only two winners and produced losses and overall a performance well below HT's normal level. The average recommended price for the each-way singles was also much higher than for the straight win selections. There were a total of 6 Double Bets (i.e. combining two horses) which roughly broke even. These are also special cases compared to the Win singles so were also excluded.
It is worth noting that including only the Win Single selections also makes the analysis easier and 'cleaner'. Because the selections are being assigned to different sets of Angles, Edges and Caveats keeping track of the data and presenting the results is already a little tricky. Splitting the categories down further by Single, Each-Way & double bets increases the amount of results to report and interpret. In the case of the Each-way selections they are clearly a different 'type' to the Win Singles just by looking at the average Price level, before contemplating the difference between the 'Win' and the 'Place' part of the bet. With Double bets you get the problem that each horse could have a different set of categories assigned making it impossible to identify a single set of positive or negative reasons underlying the selection.
The categories decided upon for the HT selections in this Study were :-
The sub-sections below follow the bullet point list to give initial results for each Angle, Edge and Caveat type. It is 'initial' because the aim at the start of the work was to see how far investigating the categorisation could be taken by simply using Strike Rates (SR, percentage of wins to runs), Return on Investment (ROI, the percentage of the total betting stakes won or lost) and commonsense. To go further than that would involve some higher level statistical analysis which would require getting external expertise involved. Before doing that it is sensible to look at the data to see whether there are any possible 'cause and effects' that can be identified.
The core of the problem is that the Second Level Edges and the Caveats can be multiply assigned, or not assigned, to each selection in any mixture. Separating out what effect an individual Edge or Caveat has when assigned, possibly randomly depending on whether HT naturally 'groups' some sets of Edges, across all the Win Single selections is really difficult. You have a lot of possible 'signals' competing with each other and the natural background static.
But, the aim of the Study is to simplify things, which means looking for effects which 'stand out' at some level. Not to do a forensic statistical analysis of the Data. Then, as Taleb and others would no doubt say was likely, end up 'proving' something to a certain level of 'Statistical Significance' but find that knowledge was useless in the real world. It is a chilling thought to face up to, if it proved true, that you could not analyse and identify any causal factors between the positive and negative reasoning HT uses and the final profits and losses. It is a little frightening to ponder the wider implications of not being able to 'back fit' what HT wrote each day.
The main point to remember about the Top Level Angles is that there is only one assigned for each of HT's selections. They reflect the major positive reason cited by HT in his supporting text to a bet. The important point to remember is that because of the one-to-one relationship of Bet to Top Level Angle you could ignore all the other Edges and Caveats and just work on the Angle. This would be the complete simplification of assessing whether to bet on an HT selection or not, simply ask the question each day - How have Angles of that type done historically? If there are any worthwhile 'signals' to pick up from the categorisation they should show up here.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| SHPBTR | 97 | 18 | 18.6 | 40.2 | 9.96 | 0.66 | 6.53 | 0.05 |
| GNG | 79 | 16 | 20.3 | 45.6 | 10.12 | 0.78 | 6.63 | 0.07 |
| BTOR | 66 | 17 | 25.8 | 34.9 | 7.65 | 0.54 | 5.65 | 0.15 |
| CRSFM | 55 | 4 | 7.3 | 36.4 | 10.84 | -0.40 | 7.48 | -0.51 |
| COFOR | 51 | 8 | 15.7 | 49.0 | 10.12 | 0.74 | 6.52 | -0.02 |
| SOFOR | 33 | 6 | 18.2 | 30.3 | 9.30 | 0.20 | 6.55 | 0.12 |
| SWEL | 30 | 8 | 26.7 | 60.0 | 6.13 | 0.28 | 4.02 | -0.03 |
| SWITCH | 23 | 1 | 4.3 | 39.1 | 9.42 | -0.89 | 6.12 | -0.96 |
| TIME | 16 | 5 | 31.3 | 56.3 | 5.68 | 0.99 | 4.52 | 0.39 |
| DIST | 16 | 0 | 0.0 | 6.3 | 10.75 | -1.06 | 8.11 | -1.06 |
| RUNSTY | 14 | 2 | 14.3 | 50.0 | 8.43 | -0.07 | 5.48 | -0.29 |
| 1stHCP | 14 | 3 | 21.4 | 42.9 | 9.86 | 2.14 | 5.57 | 0.11 |
| TRNRFM | 13 | 2 | 15.4 | 38.5 | 13.65 | 0.42 | 10.38 | 0.27 |
| GNGST | 13 | 0 | 0.0 | 46.1 | 9.77 | -1.00 | 6.08 | -1.00 |
| MISCEL | 2 | 1 | 50.0 | 50.0 | 7.50 | 1.50 | 4.75 | 1.00 |
| Totals :- | 522 | 91 | 17.4 | 42.9 | 9.44 | 0.37 | 6.38 | -0.09 |
Table 2. - Top Level Angles ordered by Count (times used) - Strike Rates and ROIs
The columns in the Table are similar to those explained in the 'Scene Setting' Section above so refer to that for a fuller explanation. The first point note is that the Top Level Angles in the first column are ordered by the number of times used by HT across the 522 Win Single bets. As ever, the larger the sample the more likely that any profit or loss incurred is a 'real' effect caused by HT's use of that Angle being more assured and worthwhile. For example, for a 'Sires For Going' refusenik like B2yoR, it is gratifying to see the 'GNGST' Angle on a 0/13 record. But, it just needs the next tip assigned to that Angle to stumble into a 16/1 win in a weak race, probably where the Pedigree had no input at all, to make that into a mild profit.
The second point to note is the large number of Angles used at 15, including two in a 'Miscellaneous' bin which couldn't be places elsewhere. The target at the Study's inception was to get to around 5-6 Top Level types. Instinctively, HT cannot be on top of the data that warrants making selections based on such a wide range of pointers. There has to be more specialisation involved. Looking at the list you could make a case for putting the '1stHCP' Angle into the 'SOFOR' one and that looks ok since both are profitable.
To make the point about how such a wide range is needed, what else do you do with an HT selection text which deals with the good Time Figure a horse has run to and otherwise has no other supporting item, other than put it into a separate 'TIME' angle?
The bottom row gives the Total or Averages across all the Top Level Angles and can be used as a crosscheck and as a benchmark to judge other rows against. It is effectively the overall figures for all 522 Win Single Bets regardless of any Angle split. Looking at the ROI figures returned, at HT's recommended (Rec) Price and at Starting Price (SP), it is good to see a mix of profits and losses reflected. Going back to the sample size point it is good that 4 of the top 5 most used Angles return above Average profits. Certainly encouraging enough to dig deeper.
On the poor returns side it is interesting to see Course Form (CRSFM), Switching to a new Trainer (SWITCH) & Distance change (DIST) returning notable losses on varying total of usage. It is worth thinking about the reasons why those losses might be 'real' in the long-term. For example, the first two are often used by HT about horses who have no strong recent form, or even worthwhile form in some cases. To some extent they are 'hopeful' bets where HT has put a story together about how a horse should return to the level of form of some run an extended time into the past. With the exception of 'GNG' to some extent, as an example, the other 4 Angles in the top 5 by usage are based on a horse having shown some real positives in it's recent outings, not back into History.
The supporting reasons below the Top Level Angle are termed Edges in the Study and are grouped as Horse, Race, Trainer & Jockey and Other types. This, and the following sub-sections, contain similar information to section 4.1 for all edges. The main points to note are that up to three Horse related Edges can be assigned to each Selection Text and those can be in any combination from the full set of Horse Edges.
The Horse Edges assigned can also be in any combination below each Top Level Angle for a selection. There are 9 of the Top Level Angles which can be placed into the 'Horse' Edges to add to the 5 Edges specific to that group. That is a lot of combinations of Angles and Edges just for those two levels before considering the other Edge groups. Looking for specific Angle/Edge combinations is going to produce a lot of very small sample sizes in a large number of types. Which means the figures given here just group the 'Horse' Edges of the same type to see what the data looks like before going further.
Ideas for taking the analysis further are covered in the 'Discussion' section of the document. For example, one way to reduce the combinations is to do away with the Top Level Angle and Second Level Edge structure. Just look at all 'positives' in a flat space. We are then not bothered about any ordering between the positives. Looking at pairwise, or higher, comparisons of positive reason use then become permutations, not combinations, and a smaller number. For example, there are 2 ways to combine 'Going' and 'Time' together with an Angle/Edge structure (GT and TG) but only 1 permutation in a flat space.
At this point the intuitive thoughts bubble up thinking back to some of the ideas in the 'Pointless Punditry' article. The parts about Pundits dipping into their 'Lucky Dip' bag of tools, shoddy and unproven or otherwise, to cobble together a coherent story and 'pad' their act. HT is clearly better than that weary description and a much more skilled craftsman. But, there is just too much going on in his range of input to his selection text. How can this vast and intricately woven set of outcomes be the product of the clear, concise and consistent use of a simple algorithm taking in a few proven variables? How much of the selection text is act padding?
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| FR | 134 | 22 | 16.4 | 43.3 | 8.36 | 0.60 | 5.67 | -0.03 |
| TM | 67 | 17 | 25.4 | 50.8 | 7.58 | 0.53 | 5.18 | 0.13 |
| GG | 62 | 8 | 12.9 | 37.1 | 10.16 | -0.22 | 7.41 | -0.47 |
| CD | 59 | 12 | 20.3 | 40.7 | 8.98 | 0.18 | 6.34 | -0.11 |
| PD | 58 | 9 | 15.5 | 36.2 | 9.60 | 0.18 | 6.43 | -0.28 |
| SH | 53 | 7 | 13.2 | 39.6 | 8.89 | 0.63 | 6.43 | -0.19 |
| SO | 40 | 8 | 20.0 | 37.5 | 9.14 | 0.61 | 5.94 | 0.15 |
| OD | 39 | 6 | 15.4 | 33.3 | 10.21 | 0.55 | 6.63 | -0.06 |
| CO | 38 | 6 | 15.8 | 50.0 | 8.53 | -0.10 | 6.97 | -0.36 |
| RS | 30 | 5 | 16.7 | 46.7 | 9.47 | 0.27 | 6.08 | 0.08 |
| HD | 30 | 7 | 23.3 | 56.7 | 11.29 | 1.55 | 6.66 | 0.35 |
| SC | 22 | 3 | 13.6 | 31.8 | 7.89 | -0.16 | 5.18 | -0.36 |
| PH | 9 | 1 | 11.1 | 44.4 | 10.89 | 0.11 | 7.82 | 0.33 |
| BT | 5 | 2 | 40.0 | 60.0 | 8.05 | 1.65 | 5.85 | 1.16 |
| Totals :- | 646 | 113 | 17.5 | 42.3 | 9.04 | 0.40 | 6.21 | -0.08 |
Table 3. - Second Level Horse Related Edges ordered by Count (times used) - Strike Rates and ROIs
A initial point to note with the table is that the 'Totals' row is now different to the Benchmark seen with the Top Level Angle table. There can be multiple, or zero, Edges assigned for each HT selection so that the Totals can be above or below the benchmark for the flat set of 522 bets. Note also that the Second Level Edges use two-letter codes so that, for example, 'TM' as an Edge is the same as the 'TIME' Angle Code. Holding your cursor over the Codes in this, and similar, tables should bring up a small text summary of the code, including the equivalent Top Level Angle code, where applicable.
It is interesting to note that the 'Totals' figures for Strike Rate, Percentage Placed, Recommended Price ROI and SP ROI are very close to the benchmark figures. Remember that the table above has some of HT selections' race results included multiple times and some not used at all. Which perhaps means that the 'sampling' done of the 522 selections by the Horse Edge labels placed on them has been a large enough sample to produce solid results. In the same line of thinking the Recommended Price and the Starting Price (SP) are both a little lower than the benchmark.
To pick some points about the Edges out of the table a it is a good start to see 'Form Franked' and 'Time' at the top of the list by usage. Both also produce better ROI returns than the overall figure for the 'Horse' Edges. At the intuitive level this feels 'right'. A horse having run in recent races that are "working out well" (when properly defined) and/or having produced a good Timefigure in it's recent races feel like proper positives.
If you had to produce a set of 6 positives to solely lean on before the Study started Timefigures are definitely on it and Franked Form quite likely to be. The B2yoR results pages have a 'subsequent winner' column in them because understanding the 'shape' of a race result and how well it spread out the horses by ability is so important. In the 'spreading' sense, result shape and franking are intertwined with Timefigures. Sectional Times for the final 2-3 Furlongs of a race and the Halfway to Final Positions model that B2yoR uses are also working on a similar area in different ways. Aimed at understanding the fold and flow of an individual race and the pressures that puts on a horse's power reserves and output. Then checking how the horse performed in those circumstances.
It is also interesting to think about whether the Average Price figures for Franking and Timefigure are telling us anything worthwhile. Both are below the average which makes sense because these are mostly not 'potential' horses. They probably have strong looking recent form in the book. But, you could suggest these are tools HT uses well because they show above average ROIs.
But, looking at the table below the top two brings one or two questions. Perhaps a good thing given we are looking for a small subset of items to combine into a simple algorithm. Having a couple of 'standouts' at the top of the list by usage and both profitable means they are on the list for further study. What happens with 'Going (GG)' at third on the list? A spectacularly poor set of results. A touch baffling because 'Going' used as a Top Level Angle is one of the star performers. Why should splitting the HT selection text by a structure use solely for the Study produce that huge difference? Is the split 'real' and the divergent returns for 'Going' saying something interesting? When it is what HT is focussing on it for a tip he reads it well but then idly tosses it in as a makeweight in lots of other selections? Even then the results are just so bad that there ought to be some cause or, much worse, it is just some random effect because the samples are too small.
Looking at the other Top Level Angles on this Edge table - "CD" is very similar to the 'CRSFM' Angle and both produced below average results. 'SHPBTR (SH)' produced above solidly above average results as Angle & Edge while 'SOFOR (SO)' did much better as an Edge. 'COFOR (CO)' was like 'Going' in being terrific as an Angle but poor as an Edge. 'RUNSTY (RS)' improved to average results as an Edge from being poor as an Angle. 'SWITCH (SC)' had poor returns all while 'BTOR (BT)' had very good returns in both areas and is another positive reason built on strong recent form.
The more you look at the table the more items you can think you see. But, at some point you have to stop because you will end up cherry-picking possible results to confirm your biases, convincing yourself you can see meaningful patterns which are just natural random variation, and so on. Always worth remembering a whole table like that could be a tool to make errors in interpretation & mistaking randomness for causal interactions. So further checking is required.
Let us leave the table with a bit of cherrypicking for confirmation bias reasons. 'PD' is the Edge code for 'Pedigree' items which HT uses in two form with the most numerous being the 'Sires/Relations for Going' type. The 'GNGST' Angle produced poor results and the 'PD' Edge had below average returns although better than 'GNGST'. Which would be what you would expect if you believe the 'Sires for Going' reasoning is flawed. The 'GNGST' Angle invokes solely going related pedigree items while the 'PD' Edge also includes some 'Pedigree for Distance' type usage. There is some evidence that reading Pedigrees, very close relatives only, for hints towards what distance a horse will show it's best form at has some merit. So with the Edge uses of 'Pedigree for Distance' is watering down the toxic outcomes from going uses, obviously.
A final small table to finish this sub-section which lists the results of looking at whether each of the 522 connections was supported by zero, 1, 2 or 3 Horse Edges. The simple thinking being that if all Horse Edges HT uses really had a positive imput to the selection reasoning then 1 is better than none, 2 than 1 and so on.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| NONE | 90 | 12 | 13.3 | 33.3 | 11.23 | 0.06 | 7.44 | -0.37 |
| ONE | 196 | 40 | 20.4 | 43.9 | 9.26 | 0.52 | 6.06 | 0.02 |
| TWO | 198 | 31 | 15.7 | 41.9 | 8.97 | 0.42 | 6.31 | -0.07 |
| THREE | 38 | 8 | 21.1 | 44.7 | 8.62 | 0.13 | 5.96 | -0.15 |
| Totals :- | 522 | 91 | 17.4 | 42.9 | 9.44 | 0.37 | 6.38 | -0.09 |
Table 4. - Win Single Bets by Number of Horse Edges assigned - Strike Rates and ROIs
Table 3. showed that Horse Edges are not all equal contributors to the positive side of the balance and some have no value at all. A few might even be negatives. If you ignored the 'THREE' row in the table you could convince yourself that adding Horse Edges, as a whole, was a positive over having none. The way the Average Prices figures decline for each level is an interesting twist.
It is probably best at this stage of understanding the data to nod sagely and move on while thinking about whether the table was telling us anything worthwhile. Forget about the sensible approach for a minute and start trying to fit an explanation to the 'THREE' row and how about this. When HT thinks he has found 3 positive areas in the horse he must build up a real confidence in this tip. He really thinks he is onto something solid and this horse has a real good chance. to the point of ignoring any negatives. But, what if the system is simpler than that and the maximum amount of positive Horse Edge 'extras' you can add is between 1 and 2, say 1.382r. Then adding positive reasons is increasing the tipster's confidence but without improving the horse's chance of winning beyond some level. The Row 'THREE' problem is a warning sign of experts who are too wrapped up in their own belief in their expertise and prediction abilities. Lovely, but just a story at present.
The table below shows the usual set of information for Race Related Edges. Up to two of these Edge types can be assigned for each HT selection. Note that the split between Edges as 'Horse', 'Race', etc. related was decided on as part of the Study and does not reflect some formal split. For example, it would have been possible to just have up to 8 Edges recorded per selection and the types just an unstructured whole. During the Study it did prove useful to have the Edge splits and to have some structure to try to match HT's writing to.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| DS | 104 | 21 | 20.2 | 39.4 | 9.80 | 0.63 | 6.50 | 0.16 |
| PC | 63 | 8 | 12.7 | 47.6 | 9.64 | 0.16 | 6.75 | -0.34 |
| DW | 36 | 8 | 22.2 | 50.0 | 9.25 | 0.61 | 5.58 | 0.01 |
| LS | 36 | 6 | 16.7 | 50.0 | 7.95 | 0.49 | 4.64 | -0.31 |
| Totals :- | 239 | 43 | 18.0 | 93.7 | 9.40 | 0.48 | 6.15 | -0.07 |
Table 5. - Second Level Race Edges ordered by Count (times used) - Strike Rates and ROIs
'DS' is the equivalent of the Top Level Angle 'DIST' for a distance change believed by HT to improve the prospects of a strong run from the horse. As an Angle Distance was only used 16 times and produced poor returns from that small sample. Here the 'DS' code was used 104 times and showed good returns and perhaps suggested the Angle sample size was an issue in that result. The change in distance could be both longer and shorter and seen as a positive and was usually only around 1 furlong in distance change. If that small a variation is impacting the horse's chances as the table suggests it is an interesting confirming item in it's own right.
'PC' is used where the pace that a race is run at is likely to help the tipped horse. The two main types are firstly a front-runner in a race mostly hold-up horses so is likely to be able to get an Easy Lead. The other is a hold-up and Closer horse in a race with enough front-runners to ensure a contested lead and the front-runners likely to fade well before the finish. This Edge will often be used in conjunction with the 'RUNSTY' Angle or 'RS' Edge where a suitable pace likely in the race is clearly linked to the chances of a particular preferred Run Style succeeding. 8 of the 16 Angles assigned as 'RUNSTY' had the 'PC' Edge code also noted.
The picture that seems to emerge from looking at the Run Style and Pace assignments is of an area that does not deliver worthwhile positive input. The 'RUNSTY' Angle produced poor returns and the 'RS' code representatives were a little better but still produced a below average ROI at recommended Prices. Here we have a case where the 'PC' Edge is producing comfortably below average returns.
At the anecdotal level the method HT uses to assess the likely pace in a race often seems a lightweight and a touch on the 'hopeful' side. A quick look through the form book, and consulting his own mental Bluffer's Guide for some horses, to get a rule-of-thumb feel for what other type of Run Style users there are amongst the other runners. If, like B2yoR, you have spent a lot of time recording where horses were at halfway, how they got to that position and how the draw affected that task the approach HT uses can seem only just on the good side of arm-waving. Say you have then taken that work and built it into an 'Efficiency Handicapping' model which included predicting the exact position each horse should be in at halfway and using it got to know the large detrimental affect of not getting to the ideal position for the horse at all, or inefficiently, had on it's final performance. After all that the feeling would have to be - "Sorry Hugh, on second thoughts it is arm-waving".
Which brings us neatly onto the 'DW' code which stands for the draw a selection has. From a small sample size that Edge is returning above average ROIs which is interesting but needs a larger sample to be properly interesting. Now, one of the 'Golden Rules' that all Pundits should have tattooed on the back of their hands, or somewhere they could see regularly, would be "Talking about the Draw a horse has without talking about the Run Style it is likely to employ, is worthless". A quick check showed that of the 44 times HT cited the Run Style as a positive only the Draw was only invoked 6 times as being good. On another four occasions it was cited as a negative. Hmmm, enough said.
The 'LS' code stands for Lesser Opposition and denotes that the horse is facing some combination of less able, less well handicapped or less 'in form' horses than in recent outings. The implication being that if it just runs to it's usual level it has a strong chance of winning and add in the odd positive or two in this race set-up a win is even more likely. An odd mixed set of ROIs with above average recommended Price ROI but poor SP ROI. Possibly just a wrinkle caused by the small sample size.
Intuitively the 'Lesser Opposition' positive feels quite solid and seems like commonsense. However, it is a good point to raise a widespread issue with tipping and for this Study the particular problem of HT using so many Angles and Edges. Imagine there are 10 runners in a race and HT uses something around 50 different Angles, Edges & Caveats. Remember, ideally each one of those 50 items should be backed up by a proven body of analysed results which tell the user how to assess them and how to weight their use. For each one of the 10 runners you need to analyse all 50 items, imagine a big spreadsheet or one of the 'Race Predictor' type ticks-and-crosses affairs, but huge.
Given that, if you want to raise 'lesser opposition' as a positive for your selected horse you should be able to produce the full 9 horses x 50 factors (all individually proved & weighted suitably for their combined interactions) for the 'opposition'. Tipsters feel the urge, or are instructed to by their employers, to tip 2yos in fields full of horses that have never run and they make no attempt to go and look at them. They will pick out mostly random, and certainly unproven, factors like birthdate, sales price, the trainer "..being able to ready one first time..". and so on as crutches for their shaky guess, err... tip. Unless we can see the 10x50 spreadsheet and the background working Hugh, we think you may be involved in a version of this activity.
The core message from the last paragraph are points that could also do with tattooing somewhere - Specialise; work with a small set of Angles; do the background work to prove they work and continue to be effective; be brave enough to admit when something is not working and drop it; think creatively about new angles and have an 'R&D' arm; do not get stuck parroting the same unproven guff most use; enjoy the challenge of trying something new. Time to stop there because the 'Endnote' feeling is starting to become a bit overwhelming, along with the realisation of being in the dock with, nearly, everyone else.
The table below shows the returns when the 522 Win Single selections were split by whether and how many Race Related Edges were assigned to them after reading HT's selection text. The same table for the Horse Edges had planted the seed of an idea that 1 positive added was better than none but after that adding more positives may not have any effect. The shaped of the three rows are similar to those in the Horse table - No Edges noted produces ROI returns that are below average and adding one Race Edge produces better results and in this case on a higher sample size. The 'TWO' line is on 35 selections which is probably too small a sample to work from but fits the tentative working idea.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| NONE | 311 | 51 | 16.4 | 38.3 | 9.45 | 0.23 | 6.51 | -0.15 |
| ONE | 176 | 33 | 18.8 | 47.2 | 9.47 | 0.60 | 6.30 | -0.01 |
| TWO | 35 | 7 | 20.0 | 40.0 | 9.27 | 0.51 | 5.67 | 0.02 |
| Totals :- | 522 | 91 | 17.4 | 41.4 | 9.44 | 0.37 | 6.38 | -0.09 |
Table 6. - Win Single Bets by Number of Race Edges assigned - Strike Rates and ROIs
Table 7. shows the basic data for second level positive reasons - Edges - which are grouped under the heading 'Trainers & Jockeys'. If this were Formula 1 (F1) motor racing the Horse Edges are the size, shape, power reserves, usage profiles and other items to do with the car. As with F1 the horse (car) is the primary factor in expressed performance, by a long margin. The designers are perhaps the bloodstock agents, the engineers and mechanics are the Trainer and their stable staff. If the basic design for the car is wrong, and if you buy the wrong horses, the improvements the engineers and mechanic can make will be limited to small margins, although more than fractions of seconds per lap in horse racing.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| JK | 61 | 6 | 9.8 | 31.1 | 9.98 | -0.10 | 6.07 | -0.43 |
| TO | 50 | 8 | 16.0 | 44.0 | 12.54 | 0.70 | 8.38 | 0.01 |
| TF | 42 | 10 | 23.8 | 50.0 | 9.38 | 1.12 | 5.66 | 0.18 |
| TJ | 10 | 4 | 40.0 | 60.0 | 11.55 | 3.65 | 5.95 | 1.15 |
| LO | 7 | 0 | 0.0 | 28.6 | 10.79 | -1.14 | 8.36 | -1.14 |
| Totals :- | 170 | 28 | 16.5 | 41.2 | 10.71 | 0.61 | 6.73 | -0.09 |
Table 7. - Second Level Trainer & Jockey Edges ordered by Count (times used) - Strike Rates and ROIs
The jockeys are the drivers and an interesting question over how much difference they can make? We can use John Whiteley's figures for the average amounts and he suggests around plus or minus 2-3lbs difference. Say 2 lengths, or less, between the best and the worst of the top 100 riders or so. It can be more than that in individual races but the average is a useful reference. For example, if we are looking at 'Jockeys (JK)' being put up by HT as positives for his selections and he were always right then what would 1-2 lengths better performance, on average, look like as an improved ROI return?
Looking at the table we perhaps do not need to take the trouble to find out because selections tagged with the jockey as an Edge show poor returns. The sample sizes are low in this group all round so some caution is needed. If we look at the 'TJ' code, which means the combination of a jockey riding for a particular trainer then that is returning very good profits. One could suggest that 'JK' & 'TJ' should be combined as a single edge. Going back to the F1 analogy that is probably a bad idea because the two codes can indicate different. If the jockey is invoked as a positive just because he is considered a good rider then how much difference can he make? If the 'TJ' code indicates the trainer thinks he has a very special 'car to drive' then we should not be much bothered about who the jockey is, the horse probably has the ability to get the job done whatever.
'TF' for trainer form is the same as the Angle 'TRNRFM' and both codes produce above average results and could be combined to make a larger sample size. Definitely an area to keep on the list for further investigation. If a jockey can make the difference measured by a small number of lengths, or fractions thereof, how much can a trainer make? Much larger is the answer because he can arrange, by design or otherwise, for his horses to finish long distances behind the winner until the 'right' time.
A belief in the Trainer, and their methods, being able to be a useful Angle gains some further support from the 'TO' Edge showing a good profit. This stands for 'Trainer Other' and a catch all are to assign all references to trainer methods and results not related to recent good runs by the stable's horses. Items such as good course records, runners second time out after a break and runners in particular race types for example. Going back to the point about positive items should have some evidence to back up their effectiveness then there will often be some presented by HT, if with the small sample size problems. But, again anecdotally, B2yoR likes all this intuitively which is why you will find so much data, FRAGs and the like, about trainers approaches with their 2yo runners on the website. Bias noted.
'LO' stands for a horse having been laid out to run to peak performance in a particular race. In theory this should just be in the 'TO' coding but it has proved useful that it never did get folded in. 'LO' shows poor returns and the text HT provides normally shows that he has not cross-checked his belief that the horse has been 'laid out' for a race. It fits into the 'hopeful' category rather than being backed up by some evidence and therefore should not be within the 'TO' code.
Table 8. shows the results for splitting the 522 Win Single selections by whether they were assigned 0, 1 or 2 Trainer & Jockey Edges. The 'TWO' row in on a very low sample size and probably ignored although a positive start. The rows for the 0 and 1 assigned show a very similar format to the Race and Horse Edge tables which makes the working theory from section 4.2 seem more plausible.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| NONE | 367 | 66 | 18.0 | 41.4 | 8.88 | 0.28 | 6.18 | -0.10 |
| ONE | 140 | 22 | 15.7 | 41.4 | 10.86 | 0.55 | 7.01 | -0.08 |
| TWO | 15 | 3 | 20.0 | 40.0 | 9.97 | 0.90 | 5.43 | -0.10 |
| Totals :- | 522 | 91 | 17.4 | 41.4 | 9.44 | 0.37 | 6.38 | -0.09 |
Table 8. - Win Single Bets by Number of Trainer & Jockey Edges assigned - Strike Rates and ROIs
The 'Other Edges' group was never a solidly defined one and more an area to place positive reasons that HT used during the year which did not fit comfortably into the previous groups. Table 9. shows the results for the three Edges in this group and note that all have very low sample sizes.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| MK | 21 | 5 | 23.8 | 42.9 | 6.35 | 0.14 | 3.85 | -0.13 |
| SD | 16 | 3 | 18.8 | 37.5 | 13.25 | 0.31 | 8.61 | -0.19 |
| SA | 2 | 1 | 50.0 | 50.0 | 8.38 | 13.50 | 3.13 | 3.50 |
| Totals :- | 39 | 9 | 23.1 | 41.0 | 9.28 | 0.90 | 5.76 | 0.03 |
Table 9. - Second Level 'Other' Edges ordered by Count (times used) - Strike Rates and ROIs
'MK' stands for the Betting Market and was used when HT noted a horse had been strongly supported on a previous run. The low number of uses points towards it being a makeweight item rather than one HT systematically uses. Something added to help him believe the case he is putting together as much as anything. The uses all fail the 'previous evidence' test since HT drops into the Pundit Lite usage of there was some money for the horse last time and that must be a 'good thing'. It also fails the test of thinking about the F1 analogy and how much difference an 'MK' coding makes in terms of lengths or ratings points. That information does not exist so the 'MK' code feels more of a tipster 'confidence booster' than anything worthwhile.
'SD' stands for something different and was meant as marker were HT showed remarkable confidence in a horse or used 'exceptional' wording about some aspect of a previous performance by the horse. A low number of uses and just average returns suggest a coding to either be binned or work expended to define and use it more fully. Similar comments for 'SA' which stands for sales price and HT only used it twice to bolster his confidence. It happened to be attached to a win by Souville which was backed from 14/1 to 4/1 to win for Chris Wall as a classic example of the type of a handicap improver set up by 'quiet' runs in maidens prior to the blossoming. Not a tip that needed a 'SA' mention to add anything to it.
Back to Top of Page
The original scope of the Study included looking at the 'Eyecatchers' that HT put up each wednesday on the 'Form Factor' programme. Collecting this information proved to be too time consuming and was stopped in May 2013 as the busiest part of the Turf Season began. However, the Interim document from March 2013 did include a set of codes for the Eyecatchers because they covered a small range of types that showed up in HT's Video Review. The 'Shaped Better than the Final Result' positive that was the headline point defining Eyecatchers was retained for the daily selections. HT calling upon items he saw in his large amount of Video work to support many of the tips.
The study uses the Top Level Angle 'SHPBTR' for these positives and the Edge code 'SH'. It was decided as part of the Data Analysis to have a sub-code attached to each use of either of these codes to identify what HT felt he had seen in the replay. These sub-codes are defined in a Table in the Appendix of this document. The table below shows the results for the usual Strike Rate analysis of the 'Shaped Better' tagged selections which had each sub-code. Placing the cursor over the two letter code in the table should display a text box with a brief definition.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| TV | 40 | 11 | 27.5 | 55.0 | 8.58 | 1.44 | 5.72 | 0.53 |
| DB | 26 | 4 | 15.4 | 46.1 | 10.96 | 0.79 | 5.98 | -0.04 |
| FW | 25 | 5 | 20.0 | 28.0 | 9.70 | 0.36 | 7.04 | -0.05 |
| UK | 21 | 1 | 4.8 | 14.3 | 8.49 | -0.57 | 6.60 | -0.67 |
| GL | 20 | 2 | 10.0 | 55.0 | 9.43 | -0.05 | 6.76 | -0.48 |
| BO | 8 | 1 | 12.5 | 25.0 | 11.16 | 0.63 | 7.25 | 0.00 |
| GM | 5 | 0 | 0.0 | 0.0 | 8.00 | -1.00 | 6.07 | -1.00 |
| RO | 2 | 0 | 0.0 | 0.0 | 16.50 | -1.00 | 13.00 | -1.00 |
| Totals :- | 147 | 24 | 16.3 | 38.8 | 9.52 | 0.49 | 6.45 | -0.08 |
Table 10. - 'Shaped Better' sub-Codes ordered by Count (times used) - Strike Rates and ROIs
The first point to note about the table is how many times HT refers to his Video Review work in the selections. The percentage of the tips covered is comfortably over 25%. However the usual warning applies that when you started splitting the codes down you end up with smaller to too small samples.
With that noted it is still interesting to see 'Travel Well (TV)' and 'Finish Well (FW)' showing good returns. If you looked down the list of sub-codes in advance you would probably pick out those two as the most likely candidates to show up as positives. Both relate to horses showing real visible positives and likely to indicate a horse in good form or capable of showing more.
Conversely, there would have been a question mark over 'Unlucky in Running (UK)' because these are the classic 'hampered' runners who did not actually show anything positive. The future positive viewpoint becomes a knee-jerk response to the horse having to be 'better than the result' but without being able to quantify an amount. Such horses tend to be hyped by lots of unsubtle tipsters on the day of their next race anyway, so may not ever be available at value prices to bet on.
The only one of the bottom four codes in the table of interest in advance would probably be 'Best of Pace (BO)' and it shows a profit. In that case the horse has shown something positive in producing a near 'average' result previously despite having been put under undue pressure early in the race. The problem with that type is that they may end up getting in a pace duel again so the chances of that happening in the selection race would need to be factored in.
Back to Top of Page
Now we really are getting somewhere. Imagine you are working your way through the data for this Study putting together the first analysis after 366 days of collecting Hugh Taylor's (HT) selection texts and processing them. You have been through the Top Level Angles and there some interesting items in the results but nothing outstanding. You have worked through the second level Edges and a similar feeling. Some promising areas but all needing a bit more digging and every time you think about how to analyse the Angles and Edges together you end up feeling confused.
Tell you what, let's put that to one side for a while and have a check through the Caveats data. They are negatives and should be different as a group to the positive items and perhaps looking through those will shed some light of how to approach the ongoing work. For reasons too tedious to relate here you have to work through the Caveats in the large table following one-by-one.
The first one you do is 'BH' for the horse's behaviour being a negative in some way. A good recommended Price ROI turns up and you think to yourself, here-we-go, another table that will look a bit like all the others and without the negative connotations showing through. More possible pseudo-randomness. Then, as you work through the other codes, the mood lightens. Let us continue the story on the other side of the table after you have had a chance to look it over.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| BH | 51 | 10 | 19.6 | 39.2 | 10.41 | 0.71 | 6.84 | -0.05 |
| HI | 46 | 5 | 10.9 | 43.5 | 8.93 | -0.24 | 6.59 | -0.40 |
| DW | 31 | 4 | 12.9 | 45.2 | 10.53 | -0.05 | 7.05 | -0.34 |
| IN | 23 | 0 | 0.0 | 26.1 | 9.20 | -1.04 | 6.56 | -1.04 |
| GG | 20 | 1 | 5.0 | 20.0 | 9.08 | -0.71 | 6.19 | -0.74 |
| IM | 20 | 4 | 20.0 | 35.0 | 11.71 | 0.83 | 7.91 | 0.25 |
| DS | 17 | 1 | 5.9 | 47.1 | 10.47 | -0.76 | 6.41 | -0.84 |
| BK | 13 | 2 | 15.4 | 30.8 | 10.35 | -0.08 | 6.49 | -0.27 |
| PC | 13 | 2 | 15.4 | 38.5 | 8.96 | -0.38 | 6.57 | -0.51 |
| TF | 10 | 1 | 10.0 | 20.0 | 11.25 | -0.75 | 7.00 | -0.65 |
| RS | 9 | 2 | 22.2 | 22.2 | 7.00 | 0.06 | 5.51 | -0.14 |
| OU | 8 | 0 | 0.0 | 25.0 | 13.00 | -1.00 | 9.97 | -1.00 |
| PH | 8 | 0 | 0.0 | 12.5 | 13.38 | -1.00 | 8.91 | -1.00 |
| UF | 8 | 0 | 0.0 | 12.5 | 17.25 | -1.00 | 8.19 | -1.00 |
| JK | 7 | 0 | 0.0 | 28.6 | 7.64 | -1.14 | 5.27 | -1.14 |
| TO | 7 | 0 | 0.0 | 14.3 | 12.14 | -1.00 | 7.62 | -1.00 |
| DY | 5 | 1 | 20.0 | 20.0 | 12.40 | 0.00 | 8.30 | -0.30 |
| HD | 4 | 0 | 0.0 | 0.0 | 7.50 | -1.00 | 5.60 | -1.00 |
| PD | 3 | 0 | 0.0 | 33.3 | 7.67 | -1.00 | 4.33 | -1.00 |
| FR | 2 | 0 | 0.0 | 0.0 | 12.00 | -1.00 | 7.00 | -1.00 |
| RH | 1 | 1 | 100.0 | 100.0 | 4.50 | 4.50 | 2.75 | 2.75 |
| SC | 1 | 0 | 0.0 | 0.0 | 10.00 | -1.00 | 5.50 | -1.00 |
| CD | 1 | 0 | 0.0 | 0.0 | 6.50 | -1.00 | 7.00 | -1.00 |
| TM | 1 | 0 | 0.0 | 0.0 | 10.00 | -1.00 | 8.00 | -1.00 |
| MK | 1 | 0 | 0.0 | 0.0 | 9.00 | -1.00 | 7.00 | -1.00 |
| Totals :- | 310 | 34 | 11.0 | 32.9 | 10.21 | -0.23 | 6.87 | -0.48 |
Table 11. - Caveats ordered by Count (times used) - Strike Rates and ROIs
This table looks very different to all the others - all that red. It looks too-good-to-be-true (TGTBT) and like something you would draw up trying to fix the results. But, it wasn't fixed and just appeared, line by line, working through the codes. There is long tail of small sample sizes but nearly all leaning one way. The overall results across the Caveat codes come to notably poor returns for Strike Rate, Placed Percentage and both ROI types. Most of these Caveats seem to be real negatives to the horse's chances. Just why 'BH' and 'IM' (for needs to improve on recent form) show up as positives need some work to understand why they gave good returns but the negative signal from the others drowned them out.
When something seems TGTBT then the next reaction is to wonder whether it is. Perhaps something has been missed or the results misinterpreted. But, the Caveat Codes are only Labels applied to a subset of HT's selections because he has raised them in his text. If you assumed that the Caveats carried no weight, no negative drag on the horse, then they would just be labels randomly assigned through the whole set of selections. But, if you took a random sample from all 522 of HT's selections it would be remarkable if it looked like this one by chance alone.
You could write a computer program to assign labels randomly through the 522 tips in the same proportions as those for the Caveats in the table. If you then ran the random assigner multiple times and produced the table above for each one it is very unlikely any of them would look like this one, i.e. the typical 'Statistical Significance' approach. This looks real.
The next step is then to think what this actually means in applied terms. HT does know when one of his selections is facing negatives that are real and will reduce their chances of winning. Which is good and something beyond just an example of the case that it is much easier to find losing combinations in life than winning ones. There is real skill being applied.
Hang on though, HT is tipping horses that he wants to win but he knows they are being dragged back by negatives in the set-up. That means he is doing one of two things, or both. First, he is poor at assessing the Prices he should be recommending when faced with negatives on the scales. The second is that he is going ahead with tipping the horses anyway, because he has to put up tips each day even if none really qualify. The Caveats are his way of letting regular readers know this is a I-had-to-tip-something selection? But, that comes back to the gripe about using the Staking Point range of 1-5 fully or adding a 'Confidence Percentage' to the selections.
Whatever, if an aim of the Study was to find some simple Algorithms to apply to cut out the weak selections HT makes we have just fallen over a really simple one. Perhaps it wont be 366 days just put down to 'Good Science' and exploring an empty landscape.
It was at this point that the thought of lumping all the Caveats together as a 'dose' of 0, 1 or 2 arose. Since the Caveat Data pointed one-way so clearly that sort of approach ought to show up well. The table follows.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| NONE | 275 | 60 | 21.8 | 48.0 | 9.04 | 0.80 | 6.22 | 0.18 |
| ONE | 184 | 28 | 15.2 | 35.9 | 9.35 | 0.13 | 6.05 | -0.25 |
| TWO | 63 | 3 | 4.8 | 28.6 | 11.47 | -0.75 | 8.07 | -0.81 |
| Totals :- | 522 | 91 | 17.4 | 42.9 | 9.44 | 0.37 | 6.38 | -0.09 |
Table 12. - Win Single Bets by Number of Caveats assigned - Strike Rates and ROIs
The results are a little startling. No Caveats and terrific results, add one Caveat and they drop below average. Add a second and the results go over-the-cliff. To put that in context, imagine you were running a trial growing potatoes and you controlled the variables you could to be the same across all groups of plants. One group you left alone as a control sample (0), the next you gave a small dose of a possible toxin (1) and the last group a double dose (2) of the toxin.
If you produced a set of results like those in the table above in that Potato Trial, but with SR & ROI replaced with stuff like Plant Height and Tuber Yield, people would laugh when you presented the Table because it looks TGTBT. It looks fixed. But, despite checking in several ways, Table 11's contents are Real and not a Fix.
Back to Top of Page
There are items and issues considered throughout the Results Analysis Section and other parts of the article. Rather than going back over many of those points in detail, and to stop this Section being too rambling, there are two sub-sections here. The first pulls together some of the positives learnt from the Study about Hugh Taylor's (HT) approach and also some of the weak areas where his selection text appears to add no value. The second deals specifically with the use of Pedigree 'reading' to infer likely performance in a race.
One area to start with is to answer more fully the question - "If HT is already profitable long-term, why are we looking at his approach, surely he must be doing most things right"? The initial answer to that would be that even if he were doing nothing wrong, it would still be worth doing the Study. Learning what approaches underpin his success would still be worthwhile. But, after you have read the nearly 600 selection texts in this Study, most two or more times, you realise the question is the wrong way to think about things.
HT's overall Strike Rate on Win Singles is 17.4% and some of these will be where he got lucky and fallen into something which his Selection Text did not address. To balance that are the strong runs (Like Harris Tweed) who show up as losses but ran right to the HT script and better than their SPs, but did not win. However, whatever fiddling you do somewhere around 70% of his stories prove to be wrong to a some level. If you look back of at the subsequent careers of a lot of those you can find many examples where the later career shows his thinking was 100% incorrect.
Which means you can comfortably improve his record by cutting out some solid portion of the around 400 weaker, ranging down to plain bad, calls he has made. Without ever bringing current profitability or otherwise into the discussion. Given that, the question about 'Why look for weaknesses in someone profitable' is plainly the wrong way to think about the issue. HT himself rarely 'cracks' when his selections are not producing worthwhile results but these HT tweets (@HughRacing) from 7th October, 2013 & 13th January 2014 show that he would not claim there is no improvement to be found :-
One really important issue that leads on from that is to think about how much 'lazy slack' there is in the Betting Market. HT, using sub-optimal techniques and data usage in a number of areas in, probably the majority of, his selections can comfortably turn a profit. It does not give the impression that many Betting Markets are 'efficient' and certainly not even that 'tight' until the last 5-10 minutes before the off.
For those who are interested in looking further into the errors in HT's thinking that can assessed, definitely with Hindsight and at times in advance, then look through these 5 texts and see if you can spot the problems - Last Sovereign, Delores Rocket, Kikonga, Beldale Memory/Reroute and Chief Executive,
This sub-section is a place to briefly run through the Results sub-section and identify the Angles & Edges which are worth following further. The aim at the Start of the Study has been to get around 6 Top Level Angles to assess and probably around 8 Edges below that. The Study recorded 15 Top Level Angles and more than 30 second level Edges. This is clearly too high and HT is putting too many ingredients into the cooking, even for a stew.
One idea to have in mind while reviewing these Angles & Edges would be where they would be placed on a Scale which had Recent/Proven/Visible/Checked at the 'better end' and Historical/Unproven/Stats/Assumed at the other.
The Top Level Angles are covered in Section 4.1 of the document. Looking for ones to definitely keep as real positives would include 'Shaped Better' (HT's Video Review Work, but see sub-codes note), 'Going' (aptitude proven on the racecourse), 'Better than OR' (proven strong recent form) & 'Time' (form level backed up by a Good Timefigure).
Four others would be retained for further assessment - 'COFOR' (running well in recent races), 'SOFOR' (Scope to improve past current OR level), 'SWEL' (proven Southwell form) and 'TRNRFM' (trainer's recent runners doing better than the stable's average). The 'SOFOR' Angle would need some more analysis to see how the two major sub-groups below it fared. The 'SWEL' Angle could be folded into the already retained 'GOING' item, of which it is a special case. But, HT is so besotted with Southwell racing it seems reasonable to keep it separate. You do wonder what will happen to the profits from 'SWEL' when Masterful Act & Dubai Hills retire from racing but you assume HT will spot their successors coming through.
Among the Angles dropped would be items which covered Distance Changes (often only by 1f up or Down), Run Styles (an area which HT needs to address more strongly to make 'work'), a horse Switching to a new trainer and Going preference based on Pedigrees and statistics (i.e. not already proven by the subject horse).
The Horse Related Edges are dealt with in Section 4.2 and remember both that Edges are a second level below Angles and that an Angle can also be used at this second level. Looking at Table 3 for the returns from these Edges a good number have already been retained as Angles. These have to remain and means that the target of around 8 retained Edges should be defined as items not already included as Angles.
Top of the list to retain would be 'FR' for recent form being franked by the other horses in the race in their subsequent runs. An interesting wrinkle to check with HT's use of 'Franking' would be to see the sample split by horses that the subject horse beat and those they were beaten by. HT uses it, at times, for horses who were beaten by an impressive winner who has won well subsequently. This type seem a suspect use of the Edge.
Beyond that there are two possibles to keep for further assessment in 'OD' denoting the horse's Official Rating (OR) has been lowered and 'HD' for some form of headgear use. The latter of that pair B2yor is sceptical of it remaining a positive over a larger sample but has shown enough 'promise' so far.
The Race Related Edges are covered in Section 4.3 and Table 5 and seem a strong group overall but need some thought. Change of Distance ('DS') comes out well and on a reasonable sample size and has to be retained on that. The issue it raises is that the same factor was dropped as a Top Level Angle, but on a sample size of just 16. Another area where some further digging into the actual uses of a Distance change positive by HT is required.
A good Draw ('DW') and an easier race ('LS') both look promising but on smaller samples. Both would be retained but probably with a 'for further assessment' tag on them rather than being fully proven. The pace in a race ('PC') would be dropped and it links with the Run Style issue where HT would need to specialise more and research the area fully to possibly see worthwhile returns.
The Trainer & Jockey Related Edges returns are in Section 4.4 and Table 7. With Trainer Form retained as a Top Level Angle it is heartening to see another strong showing her as the 'TF' Edge. The fact that 'TO' for other trainer positives also performs well helps to increase the feeling that this is an area to retain. It also encourages further analysis of the various 'Other' types for the trainer and note that 'LO' for 'laid out for the race' is one already split out that proves a negative on a small sample. It seems noteworthy that HT does not check with the trainer about such plans but makes the assumption.
Dropping the 'JK' angle for jockeys making a notable difference feels just fine but probably not a universal opinion given how much of the racing spotlight falls on them. But, despite the small sample, when the jockey used is specifically linked to the trainer by HT ('TJ') the returns seem to improve. Which means 'TJ' would be folded into the 'TO' retained Edge and considered more as further study of that area.
The Other Edges in Section 4.5 was always seen as a 'catch-all' box to put anything else that came up during the Study into if it did not fit elsewhere. The small number of uses of the three Edges in Table 9 mean they are of limited interest. 'SA' for sales price is of limited use for individual horses and easily dropped. 'SD' for a horse showing something different in a recent run that enhanced HT's belief it had more ability to show or could handle a rise in class was an ill-thought out Edge at the start. It properly belongs under the 'Shaped Better' video review sub-codes and is possibly more of a weighting factor than an Edge in it's own right.
The fact that HT only invoked the Betting Market ('MK') 21 times in 522 selections is encouraging in some ways. If you watch the racing coverage on the TV regularly you could be brainwashed into thinking the Market should be near the top of any retained 'Angle' list. Not skulking away in an 'Others' category looking a bit lonely. When HT does use it the format is clearly the of the 'Pundit Lite' type of unquestioning, and usually unchecked, "He was well backed next time over 5f, but the drop in trip didnt seem to suit.." type. Dropped while trying to jump in the air and click the heels together.
The sub-codes below the 'Shaped better than the Final Result' positive are the equivalent of the 'Eyecatcher Types' from the Interim article. HT calls on his Video Review work to inform his selections so regularly that it makes it worthwhile to look deeper into that area rather than just having a 'Video' grouping. The sub-codes for Travel Well in a Race ('TV') and Finished the race Well ('FW') would both be retained.
The Draw Bias ('DB') and Best of the Pacemakers ('BO') would also be retained but with an 'assess further then review' tag applied. The others would be dropped, This would mean that any use of the 'Shaped Better' positive as an Angle or Edge by HT would be further assessed before being accepted as a positive for a selection.
Not much needs to be said about the Caveats in Section 4.7 and Tables 10-11. This was the most successful and informative area and made the Study worthwhile if nothing else had been learnt. The Behaviour ('BH') and Needs to Improve on Recent Form ('IM') caveats need further investigation to test how 'real' and stable their positive returns were. Other than that it seems easy to accept Caveats as a one-lump-or-two toxin dose.
| Angles Retained | Edges Retained | Main Factors Dropped |
|
|
|
Table 13. Summary of Angles/Edges retained and dropped (* = For later Review)
The table shows a brief recap of the earlier points. It should be noted that the asterisk is there to show that while those areas show promise the sample sizes are on the low side.
Only one other point to raise in this section but it is one that has niggled away before the Study started and during it. HT will often quotes statistics to support his selection, most often in the form of Strike Rates. He also uses the raw profit figure rather than Return On Investment version which needs to be changed. But the real issue is how these statistics are applied. If, for example, a sire shows a profit on all his runners on a particular surface should not the correct way to apply this be to follow all his runners on the surface as a set system? Bringing in the stat only when it suits HT to pad his case for an individual horse seems wrong. How is he selecting which qualifiers to support and which to drop? How does he check his criteria for the split are valid?
The previous paragraph might seem to have a 'bit of a nerve' coming from someone who has produced a whole document drawing heavily upon Strike Rate stats. The difference is that the aim of the Study has been to produce a system, or small number of them, to run on all qualifiers once the selection is made.
Go back a good few years to a Racing UK (RUK) race meeting coverage. Angus McNae & James Willoughby are doing the Punditising from the studio. McNae is a full-on disciple of the 'Sires for Going' (SFG) angle and it is the first thing he says about most horses in any race. He is also constantly uses the stock format of "This horse is by the sire [Mud Swimmer|Bouncing Off] therefore it will love to [get it's toe in|hear it's hooves rattle". Delete as applicable. Each sentence a plonking fact placed before you and not for discussion or agreement. No hint that the sentence might need the odd likely/possibly added let alone some form of percentage based description of how 'true' the Sire-Going link might be.
Willoughby has been a holdout on the SFG angle and usually just lets the McNae references go without comment. But, this one day he seems to be about to revolt. He looks at his good mate McNae and tentatively starts this sentence - "I'm not absolutely sure what you can read into those going stats, some of the differences are a bit small .....". His voice started low and trailed off, probably because he could see that McNae either was not listening or was failing to comprehend what he was hearing. Like trying to suggest to a devoutly religious person your own vague misgivings about there being a God.
It was a memorable moment for a couple of reasons. Firstly it was a rare chance to see some disagreement between Pundits and some discussion over the validity of a tipping tool. Secondly, it was the last, brief, show of resistance from Willoughby. Three months later he was "toe in|hooves rattling" with the rest of them. He had been assimilated. A good question to answer would be how much Willoughby was just joining the gang because it was easiest or whether he had done his own forensic analysis of the SFG stats and found them plausible.
Then turn to doing this Study and reading Hugh Taylor's (HT) selection texts daily. The realisation comes quickly that HT is on the committee for the advancement of the SFG message. Two of the small set of Pundits B2yoR values on the 'wrong' side and not obvious there is anyone else on the other side, enough to make anyone have a personal policy 'wobble'. But, going against the flow has proved a good way to find profitable positions in betting so this isn't a time to 'give in'. Here are a few examples of HT's SFG usage to provide a reference point :-
Floralys - "..because it features several US-bred newcomers to the surface. FLORALYS is one thats of definite interest switched to Fibresand on pedigree. Her sire Flower Alley, who won the Travers Stakes, is unsurprisingly a big influence for dirt in the US, and although her dam Search Mission raced exclusively in this country, Search Missions half-sister Skimming went from being unplaced in a class 3 conditions race at Wolverhampton to beating to beating the mighty Tiznow on dirt in a Grade 1 event once switched to the US.".
Cosseted - "..most of the family went very well on a soft surface, and Cosseted, a daughter of Pivotal, promises to do the same, "
Bretherton - "..on Polytrack after racing on turf first time out would have produced 11 wins from 43 runs, and a 21pt profit; its also worth noting that Exceed And Excels colts have produced a 19% profit on Polytrack whereas geldings and fillies/mares have produced a 25% loss."
Silly Billy - "It could be that he's a much better horse on Fibresand than elsewhere - his sire Noverre has a strike rate of around 16% on the surface, compared with around 10% on Polytrack - and he shaped on both his previous start here over 6f"
A point to note at the start is that HT widens out the 'Sires for Going' belief to encompass the extended family, many of whom will be no more related to the subject horse than any Thoroughbred picked at random. The Floralys example is based on HT's belief that all American sires will produce runners suited to Southwell's fibresand surface. In this example he presumably did not have the right Strike Rate statistic so instead we get a lengthy piece of Tony Morris style family history. Put yourself in the position of trying to code HT selection texts into positive and negative reasons. You have to assign this as a 'Pedigree' positive in some way but how much weight does it carry compared to the horse having run a good Timefigure last time, or all the other horses in the first six home, when the horse was third, have won subsequently?
It is also a good example to cover an important point - even if you do search through the racing data and find a Strike Rate difference and profit for runners by an individual Sire you have to be careful about just unthinkingly making a causal link between Sire and Stat. The first issue is the usual one that many of these SFG stats are based on very low sample numbers and do not stand up over a long period. Even if you think the sample size is 'large enough' and the results stable you still have to prove the link. Specifically that the difference has been caused by the genetic material the horse inherited.
For example, in the 'US sires to All-Weather' link there are other causes you could propose. Many of these imports are expensively purchased and their connections have sent them to the All-Weather to find an easy race to win because they are not good enough to win a turf race. The same pattern would show up with fashionable european sires. You have to get to the right 'cause' for any stat even if you think you are over the large hurdle of having proved something in a worthwhile manner.
The Cosseted bullet point is more of the same armwaving and what is it really adding to the case? Unquestioningly linking the sire Pivotal to soft ground generally, and bringing in the 'family' as a makeweight. But how much would a 'Pivotal' add to this specific tip even if it had some validity? For a man who recommends Taleb to read, why is HT so unaware of the 'silent evidence'? What about all the Pivotals who do not win on that surface and have not shown any preference for it? Why is Pivotal being brought up solely in the text for this selection when he could be mentioned in a large number of the texts, as both a positive or negative. This highly selective use of Sires is unsystematic, added to the validity concerns.
HT also makes play of the fact that trainer James Fanshawe had trained a lot of the 'family' who mostly "went well" on soft. Which brings in the issue of brainwashing biasing the results with SFG taking the credit when the results fall the right way. Fanshawe will be well aware of the British need to waffle about SFG, and 'families' so may prepare Cosseted to peak on soft going. Very occasionally in British racing you will hear a trainer say something like "...we thought it would be too firm for her today, given her second cousin twice removed is Mud Swimmer, but she seemed to love it..". We could probably get a lot more 'surprises' without the mental straitjackets.
The Bretherton text is baffling. The 'Exceed And Excel does great on the Polytrack' is classic SFG stuff. Wasn't it the fact that his progeny also liked firm turf that is behind the name of the 2yo Listed race winner Pyman's Theory? Whatever, the sample size HT uses in this specific example is too small and it could be another version of the fashionable sires 'Class Dropping to the AW' angle, also a piece of widespread brainwashing playing out. But, the last sentence is arguing against HT's own SFG beliefs, surely? Or do Geldings and Fillies inherit their genetic material in a different way? Perhaps the colts inherit 'blood' and the others inherit DNA codes.
In the Silly Billy quote the 'Noverre' reference is plain bogus. This is a horse selected because he has already run well on two occasions at Southwell. Trying to pin the SFG tag to it after the fact is just loading the dice.
One last example of suspect Pedigree usage in the HT texts, there are many others, to make a point about coding his selections. This quote from the selection text for Omega Omega :-
HT's heart not really in that one, you feel, probably just looking for something to throw into the 'stew'. Would you code that as a positive Angle or Edge if you read it as part of this Study? Even if you believe in some SFG positive 'push' then this example still looks less effective than some of his more confident usages. Which brings us back to the point of the correct way to use this sort of positive. Ideally HT would be setting a database field to, say, -1, 0, 1 or 2 to denote the impact of the SFG factor for every horse in the race and have some way of totalling the interactions between the various inputs. Consider the first HT example above for Floralys - why aren't we thinking about betting on all the other US bred horses switching to the Fibresand in that race as well? It was the follow-them-all approach that brought about the overall profit. What is the decision process HT is undertaking?
Time to move the discussion forward and not have it continue as two, very unequal sized, groups disagreeing about how to look through Strike Rates and interpret them. A good starting point is to ask what proof there is of the validity of the 'Sires for Going' belief? What are the foundations it is built on? The core of the argument is that if the SFG effect is so strong and universal, strong enough to survive when invoked after wandering around the Family Tree, then there should be some other evidence for it.
The field of Equine Genetics is developing quickly but there isn't any evidence of a high Heritability for Going preference. To make a comparison there is some Genetic evidence to support a link between a horse's relations, back to grandparents at very most, to make assessments of the optimum Distance requirements. One version of this is the 'Equinome' company's single gene test which trainer Bolger and his University College, Dublin partners are promoting so strongly at present. There might be money to be made if you can identify parts of the Equine Genome that do influence racing aptitude in some way and develop tests for it.
Time to put some evidence on the table and introduce a Study done in 2012 in Australia by Vets at the University of Sydney - "Heritability of Track Condition Affinity in the Australian Thoroughbred Racing Population". The following quotes from the introduction of the paper show that the SFG belief exists in Australia as well.
We can take a simple view of the word 'heritable' for our purposes and a high heritability score means the pedigree tells you a lot about the likely features of parents' offspring. In humans, as an example, Eye Colour has a very high heritability and you can say a lot about the what the percentage chances of any child having a particular colour by looking at the parents' eyes. Things are usually much more uncertain and heritability scores can range down to close to zero if you took an example like assessing the child's favourite colour. Genetics has little direct input into that.
So, here we have a team searching for evidence that would support the SFG usage. They took race records from the official source in Australia for the period 1 August, 2000 until 22 February, 2011. They only looked at horses who had raced on Turf at some point and had been with a single trainer for their whole racing career. The total sample was 31,441 different horses. They then analysed the data to produce a figure for each horse for the performance measures below :-
The 'track category rating' they refer to is the Australian equivalent of the British 'Going Descriptions'. They then took the performance figures assigned and used them to calculate a Heritability figure for the 'Track Condition Affinity' of the horses. Remember that high means the Pedigree has something to say about the aptitude and low means little input. This quote from the paper summarises their Heritability findings :-
They are getting figures for Heritability of aptitude to soft going of 3-4% which is too low to be interested in. The figure they quote from a paper on Distance aptitude is around 60% for comparison. The figure for human eye colour would be a good way above 90%. The paper's authors go further and explicitly state :-
To paraphrase, we can all agree that the Sire and Dam make real contributions to amount of racing ability a horse has but they make no notable input to whether their offspring like or dislike running on soft turf. Making the going preferment seem closer to a human choice over a favourite colour. The really interesting question is what is it that is causes some horses to perform better on some types of going if it isn't the 'Pedigree'. A fascinating subject now we have the Pedigree blinkers removed and the paper raises some interesting candidate factors. What it shows for analysing horse races is that you should invoke the going after a horse has shown a liking for it and not in advance by waffling about the pedigree. Something else for the tattoo parlour visit.
Now, this is one paper and someone who really wants to defend the SFG approach could take some time to consider it and pick out some of the weaker areas in the study. Perhaps suggest ways to improve the study techniques because they are masking the SFG effect. Perhaps we could do a similar study using British Data for the same period. That would help to assess whether the situation is the same in Britain or perhaps show a different set of results. Suggesting that Australian Racing is different in some way to the British version.
But, the real point is that we would be doing something useful to extend our knowledge and put some foundations into British punditising. Not spending the rest of our lives "toe in & hoof rattling" away thoughtlessly and invoking the power of 'Sires for Going' in an ad hoc manner whenever we need another crutch to encourage us to have a bet.
Back to Top of Page
While the knowledge and insights gained from doing the Study was interesting in itself, the main aim was always to identify some simple algorithms which could be applied to Hugh Taylor's (HT) selections. Effectively trying to prove that if you cut down the text HT produces each day to a few numbers representing the meaningful parts, and cutting out the padding, you could improve profitability. This section is the place to record the first set of trials following on from the Study and also to note some areas of wider work.
The simplest algorithm that will be applied will be to ignore all the positives and padding and instead just weight the selections by the number of Caveats they contain. Only bet on those selections with no worthwhile Caveat add by HT. This is Trial 1.
The aim of the next trial will be to test how well the most promising, and apparently most 'proven', positive Angles and Edges. At present these will be kept separate from the Caveats so that a selection in Trial 2 and the negative 'drag' of the Caveats placed to one side for the Trial period. The will cover the Angles and Edges in Bold Text in Table 13. These will combined in a simple 1 extra point per Edge method. As a piece of further work the positives in normal text in that Table will be recorded but not form part of the full Trial.
The next step is to identify any further useful work to improve the Algorithms or to define new ones. In the sub-sections to the Results Analysis Section there were Table showing how treating all positives, and the negative Caveats, as just 'doses'. Effectively a positive adds one point and a Caveat takes one away. Section 4.6 showed how the Caveats produced strong results even when the positive side was ignored. The table below shows the returns if you just treat every Angle or Edge noted as +1 point and ignore the Caveats.
| TYPE | COUNT | WINS | SR % | % Placed |
Rec Av Prc |
Rec ROI |
Ave SP |
SP ROI |
| ONE | 31 | 3 | 9.7 | 32.3 | 12.05 | 0.11 | 8.28 | -0.34 |
| TWO | 102 | 17 | 16.7 | 35.3 | 8.75 | 0.05 | 5.95 | -0.24 |
| THREE | 195 | 36 | 18.5 | 44.1 | 9.50 | 0.31 | 6.56 | -0.05 |
| FOUR | 140 | 25 | 17.9 | 42.9 | 8.93 | 0.66 | 5.96 | -0.05 |
| FIVE | 48 | 8 | 16.7 | 43.8 | 10.57 | 0.13 | 6.88 | -0.07 |
| SIX | 6 | 2 | 33.3 | 50.0 | 8.79 | 4.67 | 4.21 | 1.08 |
| Totals :- | 522 | 91 | 17.4 | 41.4 | 9.44 | 0.37 | 6.38 | -0.09 |
Table 14. Summary of Returns with Positive items treated as doses
Some support in that Table for the 'More is More' take, up to a point, and the dose of Six should be ignored because of the low sample level. The Table provides a starting point for a couple of lines of further thought. The first is the obvious one of what the results are if you extend the dosing to merge positives with negatives. The Table also provides a reference point to start doing comparing some weighting of the positive factors. At present the two simple trials assume each factor is just +1 or -1. Some positive factors must add more weight than others but how to identify that?
At present those those thoughts are at an early stage and the problem of how to weight Edges under different Top Level Angles is a tricky one. One possible solution is some research level statistical methods but preferably that could be avoided for the reasons stated previously. Some other tentative ideas :-
A closing point to note is to hope that Hugh Taylor never reads any of this document, and if he does it does not change anything he does. If it did then there would be a feedback path which meant the Study work might be changing the subject it was trying to characterise and measure as it went.
Back to Top of Page
The Discussion Section tries to lay out what this Study found out and what parts can be relied on to be turned into prospective Algorithmic systems. But, at various times working through the Study data a feeling kept arising that perhaps there was not that much to learn here and the data being over-interpreted.
This began as a vague 'gut feeling' that returned at different times through the work. Initially it was hard to hear the message that the adaptive unconscious was trying to push up to the conscious. After the third time of getting this feeling the conscious had now seen enough to join-the-dots to what the subconscious had been fretting about for some time. To put it in the positive form the phrase becoming visible was that "The only thing Hugh Taylor (HT) knows with some certainty is which of the actual odds available on horses, early on the day of the race, represent good value".
To go back to the first 'Gripe' in Section 2 about not really understanding HT's insistence about there not being an 'Of Interest' list, he is actually right. The only real selection he makes about any horse is whether the price on offer in the early morning is good value. He does that intuitively and not by working through some formal process of matching a shortlist of horses identified in advance. He is extremely good at this intuitive process as his record of profits in each of the last five years, at recommended prices, shows.
The real problem for the Study, causing that odd feeling that occurred at times, is that the intuitive process may be the sum total of what is going on. Like a Grand Master who can look at a position on a Chess Board and in a 'blink' grasp what is going on and the best next move. The Chess Master has spent thousand of hours studying Chess positions to the point where he can let his unconcious do a lot of the work without ever really stopping to think. If you asked how he did it he would either not be able to explain or would stumble through some unconvincing I-know-it-when-I-see-it stuff. Longer term readers of the site will recognise this as another example of the 'Blink' text written about in the second 'Pointless Punditry' article
HT has spent so many hours watching horse races, reading form and so on that, whether he knows it consciously or not, he can sum up a race and judge a price intuitively because of all those years of work. If you ask many people who produce pre-race 'Tissues' of prices they will not be able to explain to you how they do it. There simply wont be any formal process, it is done by intuition. B2yoR can often predict the shape of the Tissue and the prices that will be on offer in 2yo maiden races. The lack of form and general information in those events meaning market formers lean too heavily on an undertrained intuition and also any available information, such as a placed run by one horse although the level of performance was poor. In those cases, as in others in racing, if you specialise and/or work hard enough you will know where early prices are likely to be wrong.
But the worrying thing if that is the case is - What is the point of HT's selection text? If he is really making the selections on a highly trained 'gut feeling' why does he feel the need to write it? We then come to the issue that HT is essentially 'Blind' to how he is weighing up races and making selections. He needs to believe that to some level he is following a reasonable formal process even though he is engaged in more of a 'Black Art'. The same way that the Medical Consultants who are outpointed by a simple, consistently applied, algorithm do.
Humans are great at concocting stories, after the fact, to make a believable structure as to why we made certain decisions. HT knows so much about racing he can easily build up a case for the selections his intuition has informed. He can draw on a wide range of ingredients to add into the stew he is going to set before the readers of his column. As the large range of codes in the results section attests to. He also knows that he needs to make the selection texts meaty and spicy enough for the readers to value them and give the right impression. It wouldn't do to say he sat there like some Mystic and "saw a horse trained by a toothless octogenarian romping home on the Lingfield AW" because 'I just know' that the old geezer has been setting this up for months.
HT is a 'Blind Stewmaker' because he does not know himself that it is all intuition about Tissue prices. He believes in the contents of his stew as much as anyone. Although probably with the exception of the half-hearted makeweight ingredients he lobs in which add nothing to the flavour nor texture. If all that is true then looking for patterns in his category coding for positive reasoning in the Study will give inconclusive results. He will not be using them consistently and just as they come to hand to prepare a story to back up the intuition.
If B2yoR was really pressed to say what was a definite finding of the Study and could be accepted without further data then the list would only have 'Caveats' on. HT really does know when there are problems for his selections to overcome and they seem to be more consciously assessed aside from the blind intuition. Using the Caveats to weed out his 'weak' selections looks a strong possibility in the future. It still feels possible that the positive reason data, the Angles & Edges, would prove unreliable if too much credence was placed upon them on the sample sizes in this Study.
Back to Top of Page
The full data used for the Study is available in two forms. The first of those is in a Data Webpage which forms part of this article. This is a large amount of information so has been placed into a separate page. On the initial publishing of this article the Data Webpage it links to is termed 'Data 1' because it does not contain the assigned Angle & Edge Codes nor the final result of the race. This has been done to enable anyone who wishes to carry out some cross-checking of the B2yoR work, or carry out their own Study, to do so without being affected by already 'knowing the answer'. After a reasonable period the 'Data 2' Webpage will be published.
B2yoR will gladly assist anyone wishing to get suitable data to undertake some form of their own coding Study. The 'Data 1' webpage' is one resource but B2yor will, of course, assist with suggestions for sub-sets of the data to cross-check and other reasonable requests. Please use the B2yoR Contact E-mail or via Twitter (@B2yoR), for making requests.
The second way to get the data is as a Database or Spreadsheet file in some format depending upon the best mutual solution. Again, please use the Contact methods noted in the previous paragraph. In an ideal world any output from use of the shared data provided would also be reciprocally shared. B2yoR realises that is unenforceable but, as a minimum, insists that people do not simply pass off other's work and efforts as their own.
Back to Top of Page
Note that in the terminology of the Study the Top Level reasons for selecting a horse are termed 'Angles' and the factors at the levels below that termed 'Edges'.
The aim after writing the Interim Document in March 2013 had been to reduce the number of Codes at both the Top Level and levels below that. That has not proved to be possible and Hugh Taylor (HT) really does use a very wide range of angles & edges. Although a set of around 5-6 top level Angles account for the majority of selections. It was decided that rather than trying to place angles or edges into larger groupings the wider range was actually the correct solution to avoid obscuring some of HT's thinking. The large range of items that HT invokes in his selection text is saying something important about his methods and blurring the distinctions unhelpful. The question of whether this large range is a 'good' or 'bad' thing is addressed in the 'Discussion' section.
A) TOP LEVEL ANGLE CODES
| Angle Code | Description |
| 1STHCP | Horse in it's First Handicap Race. Typically on 4TO after three qualifying runs. The reasoning should highlight why the horse should be capable of performing above the level it has shown so far. |
| BTOR | Better Than OR. A horse with recent form which HT believes proves it can perform to a level above it's current BHA rating (OR = Official Rating). For example, HT's opening sentence might say a horse is "well ahead of the handicapper..". |
| COFOR | Competitive Off OR. A horse that has looked "in form" in it's recent outings without appearing notably better than it's OR. The supporting reasoning should highlight why the horse is a value price in the day's race set-up. Also used, on occasions, where it has been difficult to assign a single Top Level issue and the selection seems more a sum of a number of lesser positives. |
| CRSFM | Course Form or Course related issues. Mostly used for horses returning to a Course where they have a good overall record of have produced their best career performances. |
| DIST | A Change in Race Distance is normally used as an Edge ('DS' code) below the Top Level Angle. However, in some instances it was used as the primary reason, occasionally the sole reason, so needed a Top Level coding. Note that the positive reason for a Change in Distance could be either than the horse is racing over further, or shorter, than it's latest or recent runs. |
| GNG | Going. Used where HT bases his selection on a horse who is proven on the surface they will run on in the race. They will usually have been running on a surface that is unsuitable for them in recent outings. Note that this change could be any combination of Turf, AW & going within either type. But, note that HT sees the Fibresand surface at Southwell as an important angle and therefore a separate Top Level category is used. |
| GNGST | A Going Statistic suggests that a horse will be suited to the surface or going it will be running over for the first time in the selection race. The horse will not have run on similar conditions previously. The 'statistics' that HT invokes will typically be of the 'Sires for Going' kind and comparing the sire's Strike Rate over one surface with that on another. The validity of this use of statistics is dealt with in detail in the Discussion section. Not that, unlike the 'GNG' Angle, that fist runs at Southwell on Fibresand are included in this Angle. |
| MISCEL | A catch-all code to place one-off Angles into which cannot be placed in an existing code. Only two selections in the Study were given this coding. |
| RUNSTY | The Run Style a horse typically uses through a race. Upgraded from only being a lower level edge in the interim coding to be a Top Level Angle. The two main types would be firstly a front runner likely to get an 'Easy Lead' in a race. The other would be a hold-up horse in a race where a number of proven front-runners were likely to hook up and set too fast a pace and therefore they would fade well before the finish of the race. |
| SHPBTR | Shaped Better Than the final Result. A horse who has run better in a previous race than the placing and summary in a normal Form Book would indicate. This categorisation rests on the large amount of Video Review that HT undertakes. Note that the large number of times that HT uses this Angle meant that a range of sub-types, i.e. edges, were identified and given a coding and are outlined in a table below. By convention, it was decided that the SHPBTR Angle, even if used as a second level edge, would have a related edge recorded to define the sub-type. |
| SOFOR | Scope For Improvement Past the Current OR. Horses who do not have proven recent form that they are competitive off the OR they will run off in the race. The two main sub-groups would be, firstly, horses with few career runs whom HT thinks can still develop further for some reason. The other would be horses who have won, or been competitive, off a notably higher OR in the past. These would include horses coming back from a long injury break and also those with long losing runs resulting in their OR declining. |
| SWEL | Running at Southwell on the Fibresand Surface. Part of the 'Going' Angle but used so regularly by HT as to merit a separate Top Level category. The main sub-group would be those horses with proven Fibresand form returning to SWEL having run elsewhere recently. |
| SWITCH | Switch to another Trainer, a 'Switcher'. Used where HT believes a move to a different trainer will produce an improvement over recent form. Note that this is not used solely to indicate the first run for the new trainer. It could be as many as 3-4 runs before the horse becomes a selection if it's form seems to be steadily improving or the trainer has now found a suitable race set-up. |
| TIME | Indicating the horse has achieved a notably good Time Figure in a recent outing. HT produces his own Time ratings for most All-Weather (AW) racing and for some Turf meetings. |
| TRNRFM | Trainer Form. For a trainer whose recent runners have been competing better than the stable average. |
B) SECOND LEVEL EDGE CODES
The Second Level Edges are split into four types, with items in groups relating to the Horse, the Race, the Trainer and Jockey plus a catch-all Other set. In recording positive factors invoked by HT the format that developed in the Study was to record up to 3 Horse factors, up to 2 for each of the Race and Trainer/Jockey factors and one, at most, for the Others. As with the Top Level Angles it was not possible to reduce the number of Codes from those identified in the Interim Document. Again, the wide range of factors HT uses proving to be informative in it's own right.
Note that Top Level Angles described above can also be Second Level positives below another Top Level Angle. The Edges have two letter codes, not the longer ones for Angles. Therefore the Top Level Angle codes, as two letters, are included in this table for reference but their description is not repeated.
| Reason Code | Description |
| HORSE Related Reasons :- | |
| CD | The Top Level Angle CRSFM. |
| BT | The Top Level Angle BTOR. |
| CO | The Top Level Angle COFOR. |
| FR | Form Franked. Used when other horses from a previous race the selected horse has have run in have gone on to win, or run to a competitive level, in their subsequent outings. |
| GG | The Top Level Angle GNG. |
| HD | Headgear. Where is horse is running in some form of Headgear which HT believes will improve it's expressed race performance. |
| OD | OR Down. The horse will be running off a lower Official Rating than in recent outings. |
| PD | Pedigree. Where the horse's pedigree suggests it will be suited to the conditions of the race. For example, 'Sires for Going' or a horse stepping up in distance with a pedigree which suggests this is a positive. Occasionally it will bring siblings in as part of the reasoning. |
| PH | Used where a Physical reason has been brought in to support a selection. |
| RS | The Top Level Angle RUNSTY. |
| SC | The Top Level Angle SWITCH. |
| SH | The Top Level Angle SHPBTR. |
| SO | The Top Level Angle SOFOR. |
| TM | The Top Level Angle TIME. |
| RACE Related Reasons :- | |
| DS | The Top Level Angle DIST. |
| DW | Draw. The horse either has a very good draw in the day's race [for it's Run Style?] or has been hindered by wide draws in recent outings. |
| LS | Lesser Opposition. The selected horse will be facing less able opponents than in previous outings. This could be because it is in a lower Class race or simply because the assembled field is mostly uncompetitive off their ORs for various reasons. |
| PC | Pace of the Race. How fast the subject race is likely to be runs. Depending upon the horse's Run Style this could mean a slower, or faster, than average pace. |
| TRAINER/JOCKEY Related Reasons :- | |
| JK | Jockey. HT believes the jockey used will give the horse an advantage in the race. Sub groups include the use of Apprentices claiming weight allowances whom HT rates as better riders; the use of a highly rated professional jockey after amateurs or lower ranked professional have ridden recently; the use of a jockey thought to be adept at riding a certain course or delivering a certain type of Run Style which will suit the horse. |
| LO | Laid Out for this race. Used when HT believes the horse may have had it's training designed so that it's performance peaked on the day of the race. Examples so far indicate that HT does not contact the trainer to check the view is correct. |
| TF | The Top Level Angle TRNRFM. |
| TJ | Trainer & Jockey combination. Occasionally used by HT when noting that a trainer has a notably high Strike Rate when engaging the use of a particular jockey. The implication being that the trainer would not 'trouble' the jockey unless the horse was thought to be competitive to win the race. |
| TO | Trainer Other. Catch-all for other reasons HT assigns to being solely down to the trainer's choice. |
| OTHER Reasons :- | |
| MK | Market Support. Denotes that HT feels the horse has been the subject of Market Support in some previous runs. Usually couched in the "well backed" format. [How is significant support judged?] |
| SA | Sales Price. Where the high price a horse has sold for at a a public auction is cited as a positive. |
| SD | Something Different. Catch-all item for recording that some other positive is not just 'noteworthy' but better than that. For example, below the 'SHPBTR' Top Level category the strength of finish a horse produces, or perhaps the high confidence, probably unusually so, of connections gleaned from public sources. |
C) SECOND LEVEL EDGE CODES BELOW THE 'SHPBTR' TOP LEVEL ANGLE
The 'Shaped Better than the Result' (SHPBTR) Top Level code, or the equivalent 'SH' second level code, were used by HT in more than 100 of his selections in the Study. The importance of this positive factor meant that it was sub-divided into it's own set of Second Level codes. The decision was taken to always pair up the use of 'SHPBTR' or 'SH' with a second level code which described the type of 'Shaping Better' HT then went on to detail. These pairing codes are very similar to the 'Eyecatcher' codes, both based on HT's video review activities, covered in the interim document.
| Angle Code | Description |
| BO | Best Of Pace. A horse who sets, or is involved in, too strong a pace in the early stages of a race but produces a better than average effort given that. Will usually do best of the prominent runners in terms of final placings. The winner and placed horses in the race will typically have been in the midfield or further back at halfway. |
| DB | Draw Bias. Used where a horse's solid run can be upgraded because it ran on the slower part of the course or was forced to race wide around a bend. Also used when a horse has performed badly but the effect of the Draw/Track bias excused the run's outcome. |
| FW | Finished Well. A horse that produces an unusually strong finish in a race. Often the eyecatcher will pull clear of the other runners in the last one furlong. |
| GL/GM | Got Going Late /Maiden. Usually denoting a horse that was held up in the midfield or rear of a race that was run at a slower pace. The horse will then struggle to make ground in the later race 'sprint' but will still be going forward, relative to the other runners, at the line. May indicate a horse that needs a longer trip or a stronger pace in the race. On occasions it denotes an inexperienced horse in a maiden race who realises what is required too late in the race and produces a solid late finish. In that case the GM code will be used. |
| RO | Ran Ok. Used when it is not clear from the Video and the notes that the horse did anything notable in the race. The positive reasons added will often identify what may be the underlying cause of this horse being an eyecatcher. For example, a trainer switch and the horse has just 'run ok' but better than it had been for the previous trainer. |
| TV | Travel Well (& then Fade). Horses that are noted travelling well in early race but then fade to finish well back. Sub-groups include handicapped horses who need a shorter trip, faster going or need the run to regain full race fitness. It can also be used for inexperienced horses in maiden races. |
| UK | Unlucky in running. The classic eyecatcher group whereby a horse is stopped from producing it's full effort by being blocked by other runners. The horse making ground on a rail who gets cut off and the jockey has to stop riding, for instance. Intuitively, these ought to fail the test of being difficult to find in a normal Form Book. They will be widely known and may well be overbet on their next outing just because of being 'unlucky last time' without anyone trying to quantify how much they should be capable of. The unsubtle end of 'eyecatching'. |
D) CAVEAT CODES
As well as noting positive reasons in support of his selection's chances he will often raise items which could be detrimental to the performance of the horse. These are termed 'Caveats' for the Study. A range of the positive factor codes already described could be raised as a negative so will not be repeated in the table below. For example a change in race distance for the selection when the horse has never run over the distance. The table covers the Caveat Codes which are never used as positives so did not appear in the earlier tables.
| Caveat Code | Description |
| HORSE Reasons :- | |
| BH | Behaviour. Highlights problems with the horse's general attitude which may prevent it from displaying it's full ability. For example, a horse that gives trouble loading into the stalls or makes slow starts would be noted by this item. |
| BK | Break since last run. The horse is running very soon after the previous outing or after a long period since the last run. |
| IM | The selection needs to improve on it's recent, or career, form level to be able to compete to win. |
| IN | The horse has shown inconsistent form levels during it's career. |
| OU | OR Up. A horse running off a higher Official Rating that it has not proved it can be competitive off. In theory could be seen as the opposite of the positive 'OD' item but 'OU' a clearer way of highlighting the caveat than negating a positive. Also, unlike a Distance Change for example, an increase in OR should not ever be seen as a 'positive' so 'OU' is an independent item from 'OD'. |
| UF | Unproven Form. The horse has not shown any worthwhile form during it's career or a recent run which looked improved may have been mis-read in some way. Not just the opposite of 'Form Franked'. For example, HT might say that a 4TO horse in it's first handicap might actually be as "useless" as the first three outings have suggested. In another case HT might say that a horse returning from a long break or injury may simply not be capable of the same level of form anymore that it had previously shown. |
| RACE Reasons :- | |
| HI | Higher Class or In-Form Opposition. The horse is running in a better class race or against tougher opponents than in it's recent races. |